
kubernetes 架构
分层架构
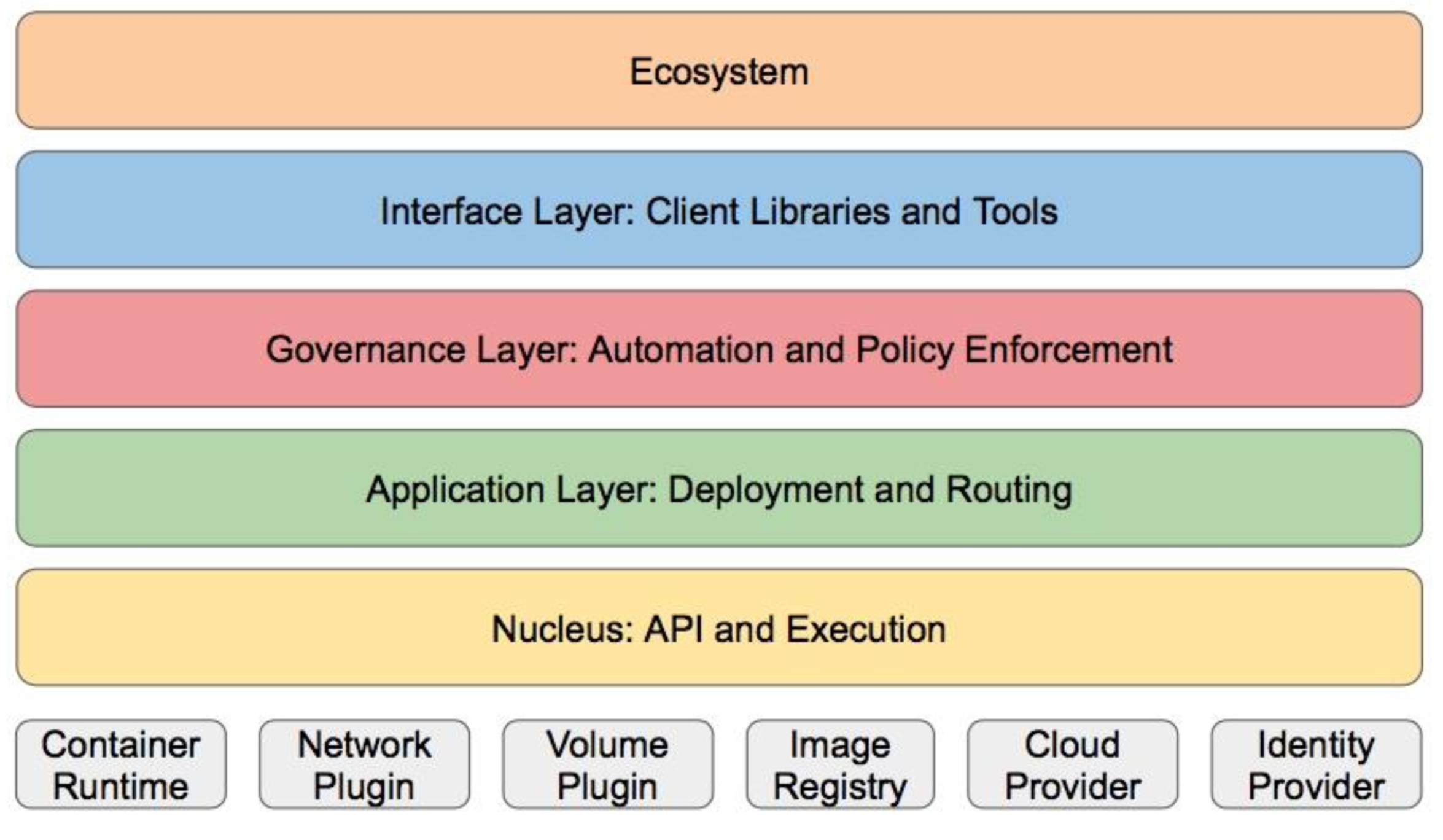
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供 插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路 由(服务发现、DNS解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩 展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)
接口层:kubectl命令行工具、客户端SDK以及集群联邦
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为
两个范畴 :
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用 、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、CloudProvider、集群自身的配置 和管理等
架构设计优缺点
优点
- 容错性:保证Kubernetes系统稳定性和安全性的基础
- 易扩展性:保证Kubernetes对变更友好,可以快速迭代增 加新功能的基础。
- API分版本,API可自由扩展(CRD)
- 插件化,调度器,容器运行时,存储均可扩展
- 声明式(Declarative)的而不是命令式(Imperative): 声明式操作在分布式系统中的好处是稳定,不怕丢操作 或运行多次,例如设置副本数为3的操作运行多次也还是 一个结果,而给副本数加1的操作就不是声明式的,运行 多次结果就错了。
缺点
配置中心化:所有状态都保存在中心的etcd上,而非分布
式存储,性能有一定制约
单体调度:调度一致性好而吞吐低
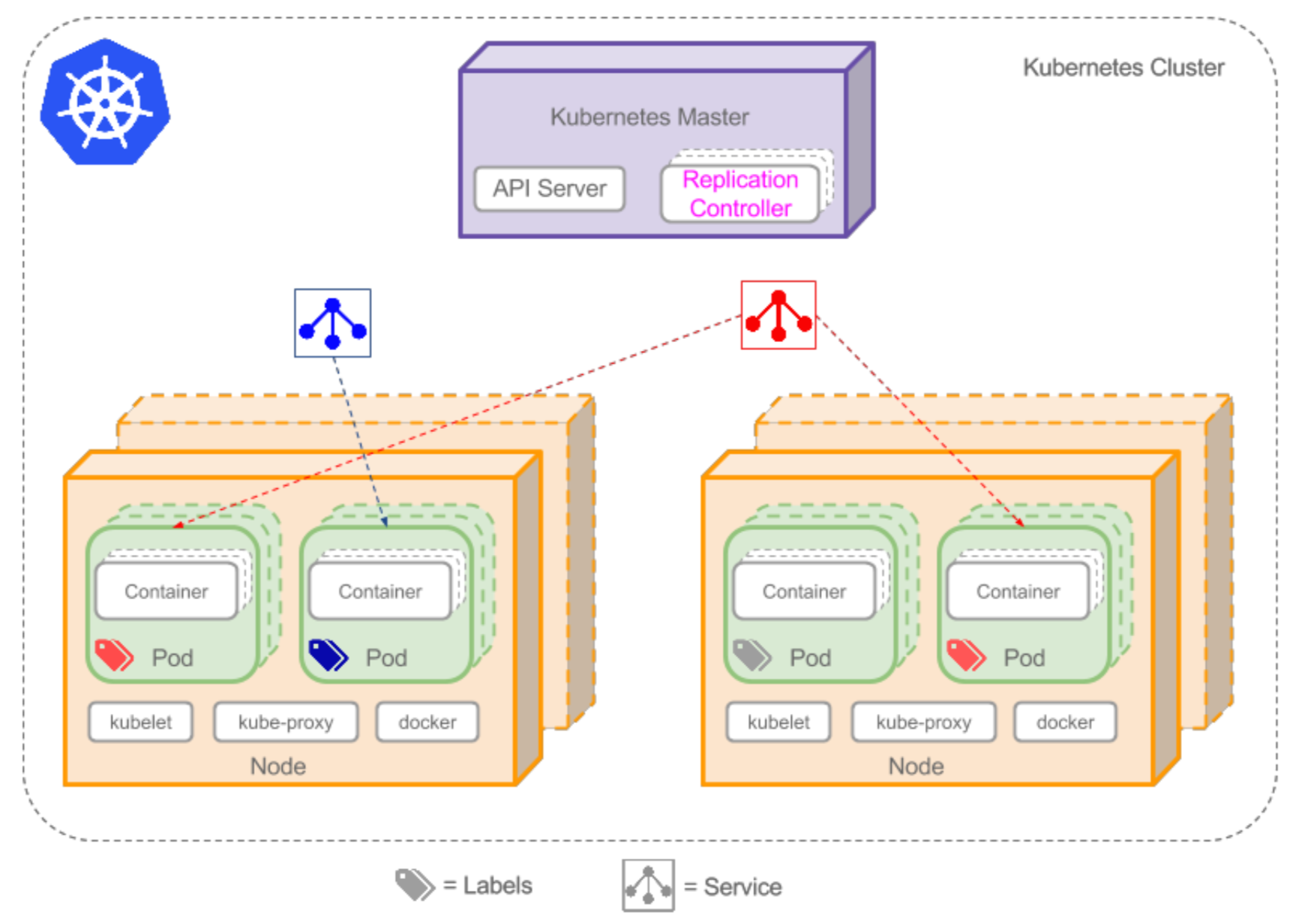
k8s提供的抽象
| EN | CN |
|---|---|
| Container | 容器 |
| Pod | 容器组 |
| ReplicaSet | 副本组合 |
| Service | 服务 |
| Label | 标签 |
| Node | 节点 |
Pod
- Pod是在Kubernetes集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod的设计理念是支持多个 容器在一个Pod中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务 。Pod对多容器的支持是K8最基础的设计理念。比如你运行一个操作系统发行版的软件仓库,一个Nginx容器用 来发布软件,另一个容器专门用来从源仓库做同步,这两个容器的镜像不太可能是一个团队开发的,但是他们 一块儿工作才能提供一个微服务;这种情况下,不同的团队各自开发构建自己的容器镜像,在部署的时候组合 成一个微服务对外提供服务。
- Pod是Kubernetes集群中所有业务类型的基础,可以看作运行在K8集群中的小机器人,不同类型的业务就需要不 同类型的小机器人去执行。目前Kubernetes中的业务主要可以分为长期伺服型(long-running)、批处理型( batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application);分别对应的控制器为 Deployment、Job、DaemonSet和PetSet。
副本集 (Replica Set,RS)
Replica Set:Kubernetes集群中保证Pod高可用的API对象。 通过监控运行中的Pod来保证集群中运行指定数目的Pod副本 。指定的数目可以是多个也可以是1个;少于指定数目,RS 就会启动运行新的Pod副本;多于指定数目,RS就会杀死多 余的Pod副本。即使在指定数目为1的情况下,通过RS运行 Pod也比直接运行Pod更明智,因为RS也可以发挥它高可用 的能力,保证永远有1个Pod在运行。RS适用于长期伺服型的 业务类型,比如提供高可用的Web服务。
服务 (Service)
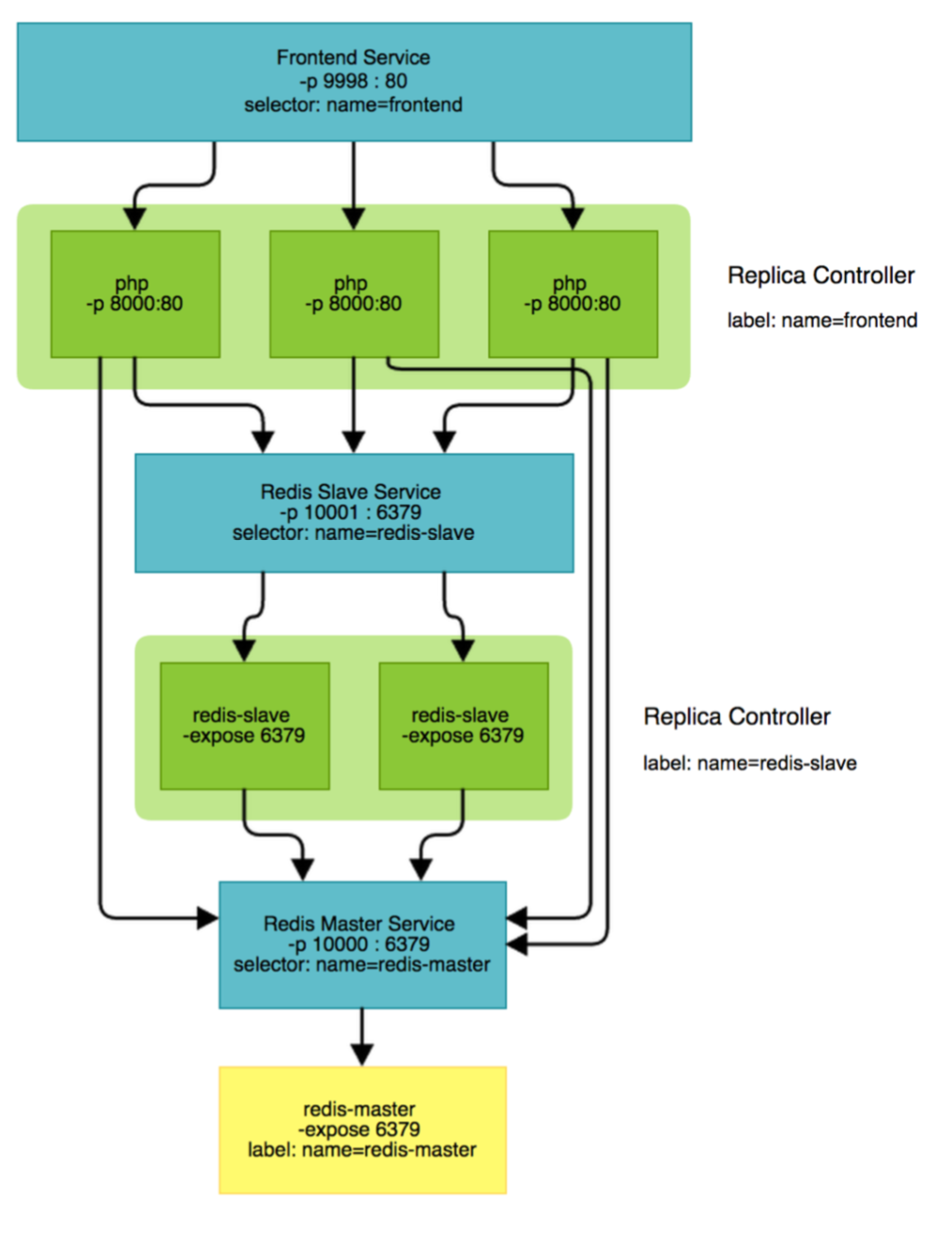
RS只是保证了支撑服务的微服务Pod的 数量,但是没有解决如何访问这些服务 的问题。一个Pod只是一个运行服务的 实例,随时可能在一个节点上停止,在 另一个节点以一个新的IP启动一个新的 Pod,因此不能以确定的IP和端口号提 供服务。要稳定地提供服务需要服务发 现和负载均衡能力。服务发现完成的工 作,是针对客户端访问的服务,找到对 应的的后端服务实例。在K8集群中, 客户端需要访问的服务就是Service对象 。每个Service会对应一个集群内部有效 的虚拟IP,集群内部通过虚拟IP访问一 个服务。
kubernetes 中的对象
1 | apiVersion: extensions/v1beta1 |
- Metadata:标识API对象,每个对象都至少有3个元数据:
namespace,name和uid;除此以外还有各种各样的 标签labels用来标识和匹配不同的对象,例如用户可以 用标签env来标识区分不同的服务部署环境,分别用env=dev、env=testing、env=production来标识开发、 测试、生产的不同服务 - Spec: 描述了用户期望Kubernetes集群中 的分布式系统达到的理想状态(Desired State),例如用户可以通过复制控制器 Replication Controller设置期望的Pod副本 数为3
- Status:系统实际当前达到的状态(Status) ,例如系统当前实际的Pod副本数为2;那么复制 控制器当前的程序逻辑就是自动启动新的Pod, 争取达到副本数为3
对象分类
| 类别 | 名称 |
|---|---|
| 资源对象 | Pod、ReplicaSet、ReplicationController、Deployment 、StatefulSet、DaemonSet、Job、CronJob、 HorizontalPodAutoscaling |
| 配置对象 | Node、Namespace、Service、Secret、ConfigMap、 Ingress、Label、ThirdPartyResource、 ServiceAccount |
| 存储对象 | Volume、Persistent Volume |
| 策略对象 | SecurityContext、ResourceQuota、LimitRange |
业界各种安装方式对比
| 安装方式 | 安装前准备 | 特点 | 高可用 | 复杂度 |
|---|---|---|---|---|
| kubeadm | kubectl + kubelet | 不对接节点,自己准备 节点环境,容易被集成 到其他工具链中 | HA(T+) | 高 |
| kops | kubectl | 对接AWS/GCE/Vmware 帮助你管理虚机 | HA | 中 |
| minikube | kubectl | 单机对接VM | 无 | 低 |
| rancher | rancher | 墙内加速,跨云能力 | 不清楚 | 中 |
| 手工 | 11+组件 | 任意集群 | HA | 疯狂 |
当pod创建时,k8s到底干了啥
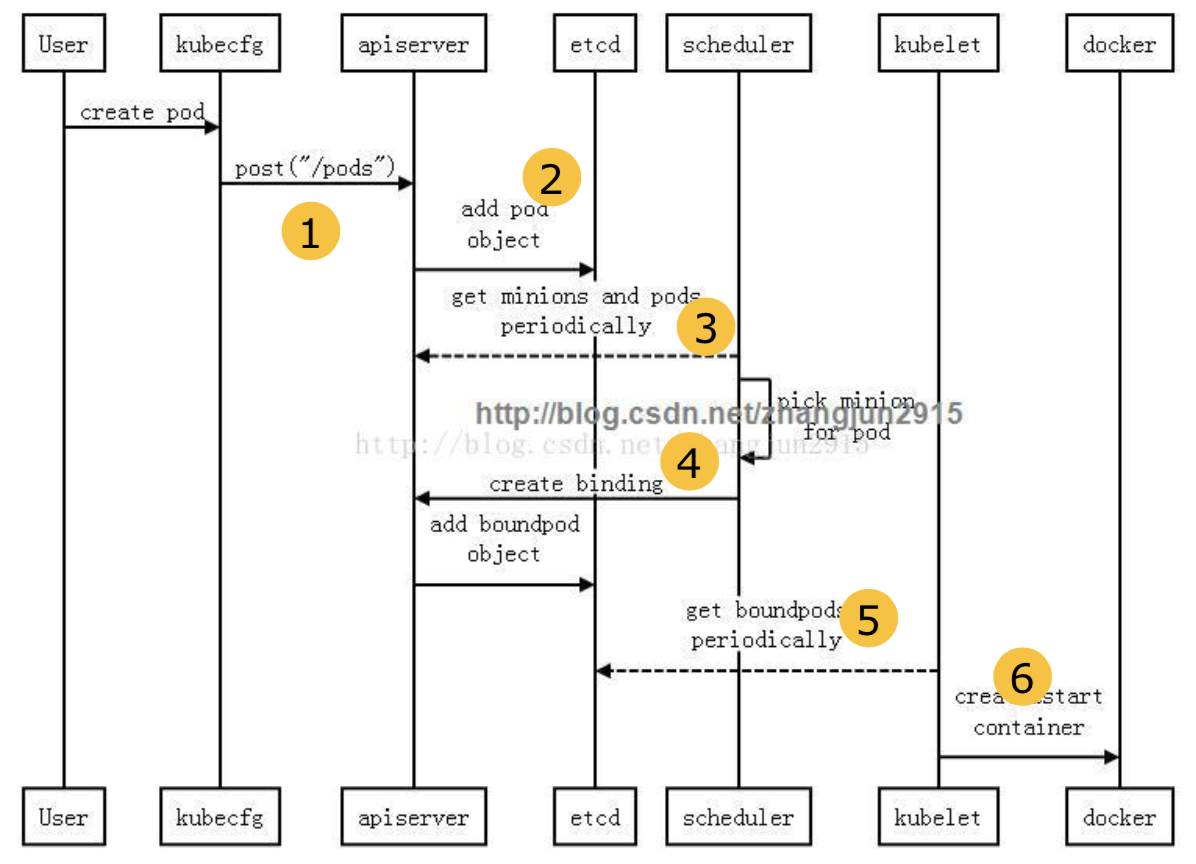
- kubectl 提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
- kube-apiserver 处理用户请求,存储Pod数据到etcd。
- kube-scheduler 通过API Server查看未绑定的Pod。尝试为Pod分配主机。
- 过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如 Pod 指定了所需要的资源量,那么可用资源比 Pod 需要的资源量少的主机会被过滤掉。
- 主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个 Replication Controller 的副本分布到不同的主机上,使用最低负载的主机等。
kube-scheduler 选择主机:选择打分最高的主机,进行 binding 操作,这个操作本质是通过kube-apisever修改Pod的字段,结果存储到etcd中。
kubelet 根据调度结果执行Pod创建操作: 绑定成功后,pod.spec.nodeName有值了。运行在每个工作节点上的kubelet也会定期与etcd同步pod信息(属于自己这个node的)
- docker接受到kubelet下发的命令,启动相应容器,至此,一个Pod启动完毕
kubectl自动补全:
2
3
> $ source <(kubectl completion zsh) # zsh下自动补全
>k8s免费在线lab网站: https://labs.play-with-k8s.com/
kubectl 常见命令
详见:Cheat Sheet
kubectl上下文和配置
1 | $ kubectl config view # 显示合并后的 kubeconfig 配置 |
kubectl 创建对象
1 | $ kubectl create -f ./my-manifest.yaml # 创建资源 |
kubectl显示和查找资源
1 | # Get commands with basic output $ kubectl get services |
kubectl编辑资源
1 | $ kubectl edit svc/docker-registry # 编辑名为 docker-registry 的 service |
kubectl Scale 资源
1 | $ kubectl scale --replicas=3 rs/foo # Scale a replicaset named 'foo' to 3 |
kubectl 删除资源
1 | $ kubectl delete -f ./pod.json # Delete a pod using the type and name specified in pod.json |
kubectl与运行中的 Pod 交互
1 | $ kubectl logs my-pod |
kubectl与节点和集群交互
1 | $ kubectl cordon my-node |
其他获取帮助的途径
使用命令
2
>使用 python
2
>
k8s构建高可用集群
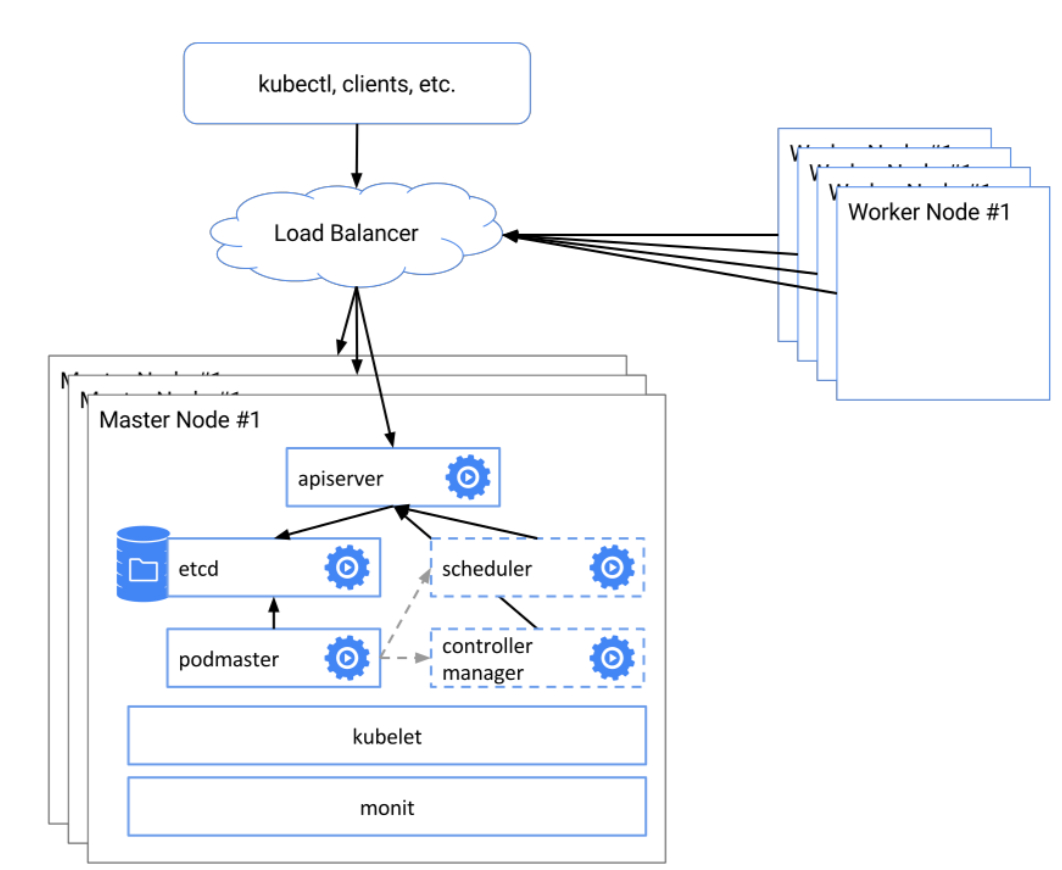
- Establishing a redundant, reliable data storage layer
- Clustering etcd
- Validating your cluster
- Even more reliable storage
- Clustering etcd
- Replicated API Servers
- Installing configuration files Starting the API Server
- Load balancing
- Endpoint reconciler
- Master elected components
- Installing configuration files
k8s应用管理
pod详解
- Pod就像是豌豆荚一样,它由一个或者多个容器组成
- Pod中的容器共享IP地址和端口号,它们之间可以通过localhost互相发现 。它们之间可以通过进程间通信,例如SystemV信号或者POSIX共享内 存。不同Pod之间的容器具有不同的IP地址,不能直接通过IPC通信。
- Pod中的容器也有访问共享volume的权限,这些volume会被定义成pod的 一部分并挂载到应用容器的文件系统中。
pod的设计动机
容器介于操作系统和应用之间,容器的推荐玩法是每个容器运行一个进程。
- 外部掌控多容器的组合和生命周期 — redhat和docker公司的控制权 之争
- 单容器多进程玩法的案例 — 阿里的pouch项目
对外,Pod作为一个独立的部署单位,支持横向扩展和复制。 共生(协同调度),命运共同体(例如被终结),协同复制 ,资源共享,依赖管理
对内,Pod内容器互相协作
pod中的应用必须协调端口占用。每个pod都有一个唯一的IP地址, 跟物理机和其他pod都处于一个扁平的网络空间中,它们之间可以 直接连通。
Pod中应用容器的hostname被设置成Pod的名字。
Pod中的应用容器可以共享volume。Volume能够保证pod重启时使
用的数据不丢失。
pod的非持久性
Pod在以下几种情况下都会被终结:
- 调度失败
- 节点故障
- 缺少资源
- 节点维护
- 用户主动干掉Pod
init容器
Init 容器是一种专用的容器,在应用程序容器启动之前运行
init 容器总是运行到成功完成为止。
每个 Init 容器都必须在下一个 Init 容器启动之前成功完 成。
Init 容器能做什么?
等待一个 Service 创建完成,通过类似如下 shell 命令:
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; exit 1
在启动应用容器之前等一段时间,使用类似 sleep 60 的命令。
Pod中容器镜像常见设置
| pod.spec.containers[]. imagePullPolicy | 镜像拉取策略 |
|---|---|
| IfNotPresent(默认) | 在没有此镜像时下载 |
| Always | 每次必下载 |
| 镜像tag设置 | 拉取策略 |
|---|---|
| Image:latest | 每次必下载 |
| image | 每次必下载 |
| image:* | 在没有此镜像时下载 |
扩展:
Pod.status.phase
| 容器状态 | 描述 |
|---|---|
| 挂起(Pending) | Pod 已被 Kubernetes 系统接受,但有一个或者多个容器 镜像尚未创建。等待时间包括调度 Pod 的时间和通过网 络下载镜像的时间,这可能需要花点时间。 |
| 运行中(Running) | 该 Pod 已经绑定到了一个节点上,Pod 中所有的容器都 已被创建。至少有一个容器正在运行,或者正处于启动 或重启状态。 |
| 成功(Successed) | Pod 中的所有容器都被成功终止,并且不会再重启。 |
| 失败(Failed) | Pod 中的所有容器都已终止了,并且至少有一个容器是 因为失败终止。也就是说,容器以非0状态退出或者被 系统终止。 |
| 未知(Unkonwn) | 因为某些原因无法取得 Pod 的状态,通常是因为与 Pod 所在主机通信失败。 |
容器探针(注意不是Pod探针)
- 探针探查方式
- ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
- 探针结果:成功、失败、未知
- 探针引起外部动作
- livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其 重启策略 的影响。如果容器 不提供存活探针,则默认状态为 Success。
- readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败 ,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供 就绪探针,则默认状态为 Success
容器重启策略
| Pod.spec.restart Policy字段 | 行为:适用于Pod中所有失败的容器 |
|---|---|
| Always(默认) | exitCode=任何数字,执行重启操作 |
| OnFailure | exitCode!=0,执行重启操作 |
| Never | exitCode=任何数字,不重启 |
以五分钟为上限的指数退避延迟(10秒,20秒,40秒… )重新启动,并在成功执行十分钟后重置。
更多信息:
2
>
pod状态与容器状态的关系
| 容器 | 退出状态 | log event | restartPolicy | 行为 | Pod.status.phase |
|---|---|---|---|---|---|
| 1个 | success | completion | Always | 重启容器 | Running |
| 1个 | success | completion | OnFailure | 无 | Succeeded |
| 1个 | success | completion | Never | 无 | Succeeded |
| 1个 | fail | failure | Always | 重启容器 | Running |
| 1个 | fail | failure | OnFailure | 重启容器 | Running |
| 1个 | fail | failure | Never | 无 | Failed |
| 2个 | 一个fail一个正常运行 | failure | Always | 重启容器 | Running |
| 2个 | 一个fail一个正常运行 | failure | OnFailure | 重启容器 | Running |
| 2个 | 一个fail一个正常运行 | failure | Never | 无 | Running |
| 2个 | 一个not running一个exit | failure | Always | 重启容器 | Running |
| 2个 | 一个not running一个exit | failure | OnFailure | 重启容器 | Running |
| 2个 | 一个not running一个exit | failure | Never | 无 | Failed |
| 1个 | out of memeory | OOM | Always | 重启容器 | Running |
| 1个 | out of memeory | OOM | OnFailure | 重启容器 | Running |
| 1个 | out of memeory | OOM | Nerver | 无 | Failed |
| n个 | 磁盘崩溃 | failure | A/O/N | 杀死所有容器 如果pod被管 控,异地重建 | Failed |
| n个 | node被分区 | failure | A/O/N | 等待node超时 如果pod被管 控,异地重建 | Failed |
ReplicaSet: 副本集
ReplicaSet是下一代复制控制器。现在ReplicaSet和 Replication Controller之间的唯一区别是选择器支持。ReplicaSet支持标签用户指南中描述的新的基于集合的选择器要求,而Replication Controller仅支持基于等同的选择器要求。
大多数kubectl支持复制控制器的命令也支持ReplicaSet。rolling-update命令是一个例外 。如果您想要滚动更新功能,请考虑使用Deployment。此外, rolling-update命令是必需的,而Deployments是声明性的,因此我们建议通过rollout命令使用Deployments 。
虽然ReplicaSet可以独立使用,但今天它主要被 Deployments用作协调pod创建,删除和更新的机制。使用“Deloyment”时,不必担心管理它们创建的副本集。部署拥有并管理其ReplicaSet。
ReplicaSet确保在任何给定时间运行指定数量的pod副本。但是,Deployment是一个更高级别的概念,它管理ReplicaSet并为pod提供声明性更新以及许多其他有用的功能。因此,除非您需要自定义更新编排或根本不需要更新,否则我们建议您使用部署而不是直接使用ReplicaSet。
这实际上意味着您可能永远不需要操作ReplicaSet对象:改为使用Deployment,并在spec部分中定义您的应用程序。
1 | apiVersion: extensions/v1beta1 |
更多信息参考:https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
K8s容器资源限制可以参考这篇:https://my.oschina.net/HardySimpson/blog/1359276
Deployment的行为和定义
Deployment为Pod和Replica Set(下一代Replication Controller)提供声明式更新。
您只需要在 Deployment 中描述您想要的目标状态是什么,Deployment controller 就会帮您将 Pod 和ReplicaSet 的实际状态改变到您的目标状态。您可以定义一个全新的 Deployment 来创建 ReplicaSet 或者删除已有的 Deployment 并创建一个新的来替换。
注意:您不该手动管理由 Deployment 创建的 ReplicaSet,否则您就篡越了 Deployment controller 的职责!下文罗列了 Deployment 对象中已经覆盖了所有的用例。如果未有覆盖您所有需要的用例,请直接在 Kubernetes 的代码库中提 issue。
1 | #controllers/nginx-deployment.yaml |
更多信息:
Deployment 文档:https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
Deployment 简述:https://jimmysong.io/kubernetes-handbook/concepts/deployment.html
Deployment常见操作
扩容:
1
$ kubectl scale deployment nginx-deployment --replicas 10
如果集群支持 horizontal pod autoscaling 的话, 还可以为Deployment设置自动扩展:
1 | $ kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu- percent=80 |
- 更新镜像也比较简单:
1 | $ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 |
- 回滚:
1 | $ kubectl rollout undo deployment/nginx-deployment |
Services
Kubernetes Pod 是有生命周期的,它们可以被创建,也可以被销毁,然而一旦被销毁生命就永远结束。 通过 ReplicationController 能够动态地创建和销毁 Pod(例如,需要进行扩缩容,或者执行 滚动升级)。 每个 Pod 都会获取它自己的 IP 地址,即使这些 IP 地址不总是稳定可依赖的。 这会导致一个问题:在 Kubernetes 集群中,如果一组 Pod(称为 backend)为其它 Pod (称为 frontend)提供服务,那么那些 frontend 该如何发现,并连接到这组 Pod 中的哪些 backend 呢?
关于 Service
Kubernetes Service 定义了这样一种抽象:一个 Pod 的逻辑分组,一种可以访问它们的策略 —— 通常称为微服务。 这一组 Pod 能够被 Service 访问到,通常是通过 Label Selector(查看下面了解,为什么可能需要没有 selector 的 Service)实现的。
举个例子,考虑一个图片处理 backend,它运行了3个副本。这些副本是可互换的 —— frontend 不需要关心它们调用了哪个 backend 副本。 然而组成这一组 backend 程序的 Pod 实际上可能会发生变化,frontend 客户端不应该也没必要知道,而且也不需要跟踪这一组 backend 的状态。 Service 定义的抽象能够解耦这种关联。
对 Kubernetes 集群中的应用,Kubernetes 提供了简单的 Endpoints API,只要 Service 中的一组 Pod 发生变更,应用程序就会被更新。 对非 Kubernetes 集群中的应用,Kubernetes 提供了基于 VIP 的网桥的方式访问 Service,再由 Service 重定向到 backend Pod。
1 | kind: Service |
应用流程:后端匹配→代理→发布→服务发现→客户端
Services → Pod → Endpoints
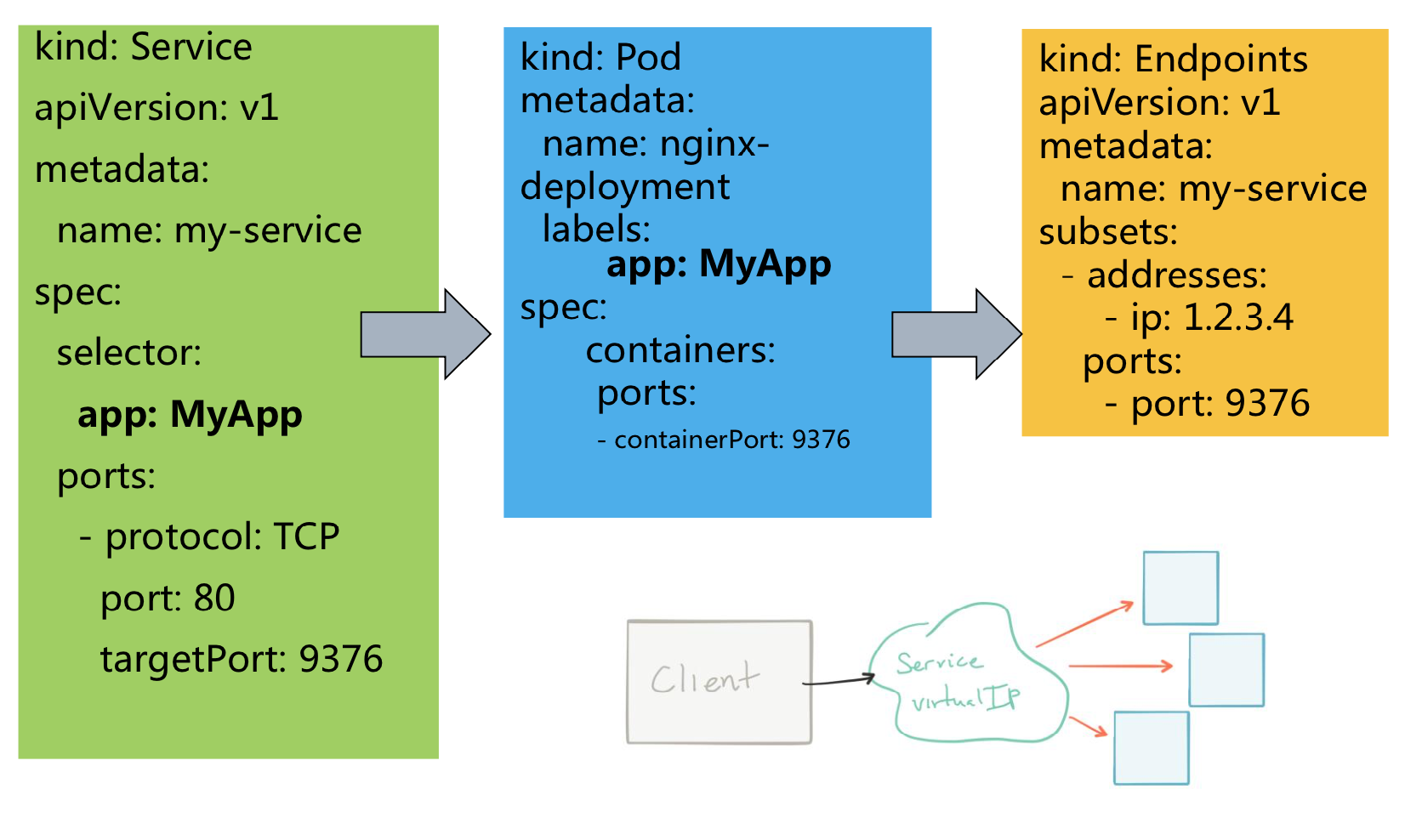
由于userspace使用并不常见,因此不在此赘述。
更多详见:https://jimmysong.io/kubernetes-handbook/concepts/service.html
Service的发布类型
对一些应用(如 Frontend)的某些部分,可能希望通过外部(Kubernetes 集群外部)IP 地址暴露 Service。
Kubernetes ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下:
ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的ServiceType。NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort服务会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求<NodeIP>:<NodePort>,可以从集群的外部访问一个NodePort服务。LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。ExternalName:通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。 没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的kube-dns才支持。externalIPs:如果外部的 IP 路由到集群中一个或多个 Node 上,Kubernetes Service 会被暴露给这些 externalIPs。 通过外部 IP(作为目的 IP 地址) 进入到集群,打到 Service 的端口上的流量, 将会被路由到 Service 的 Endpoint 上。 externalIPs 不会被 Kubernetes 管理,它属于集 群管理员的职责范畴。
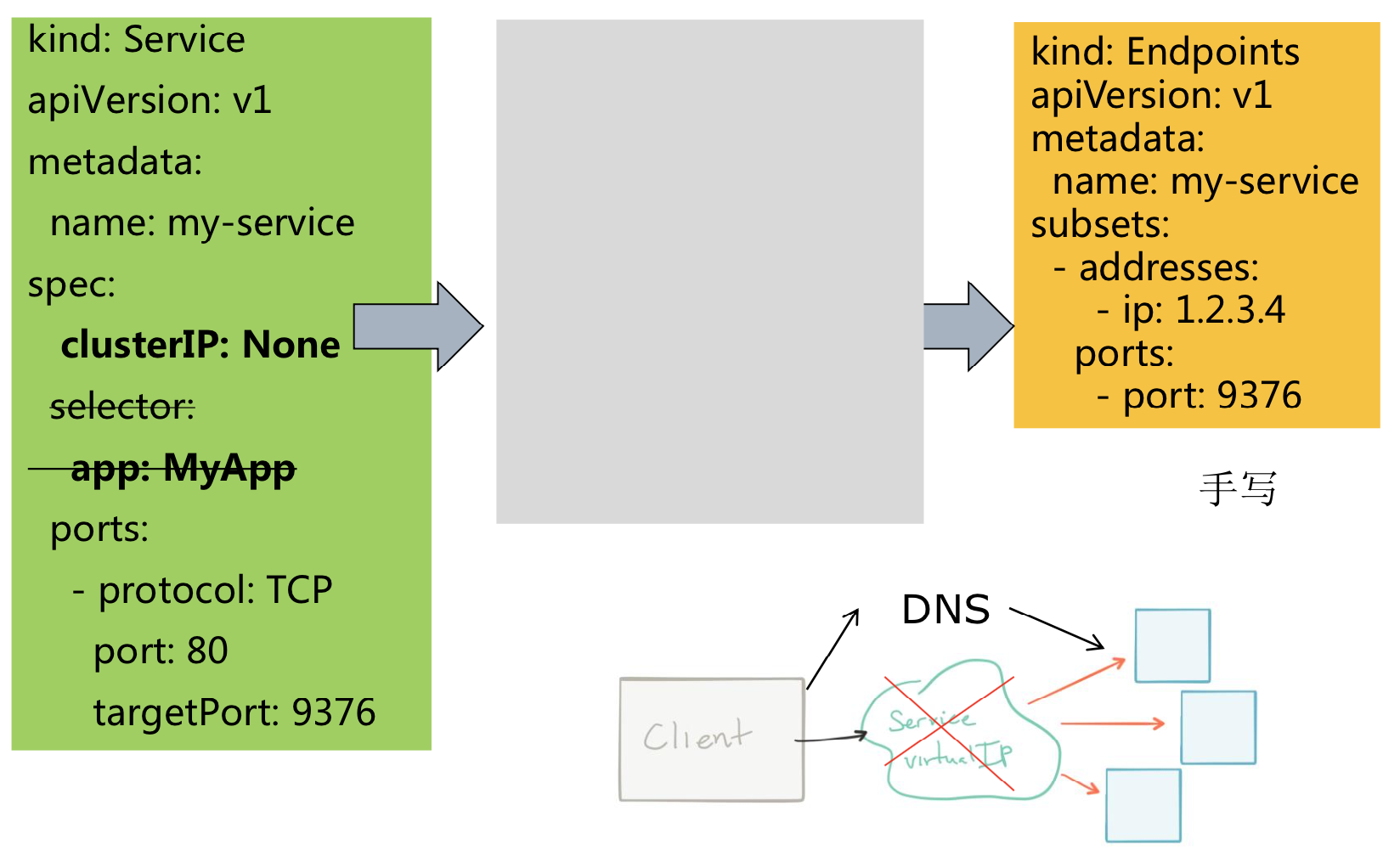
Services → 无Selector
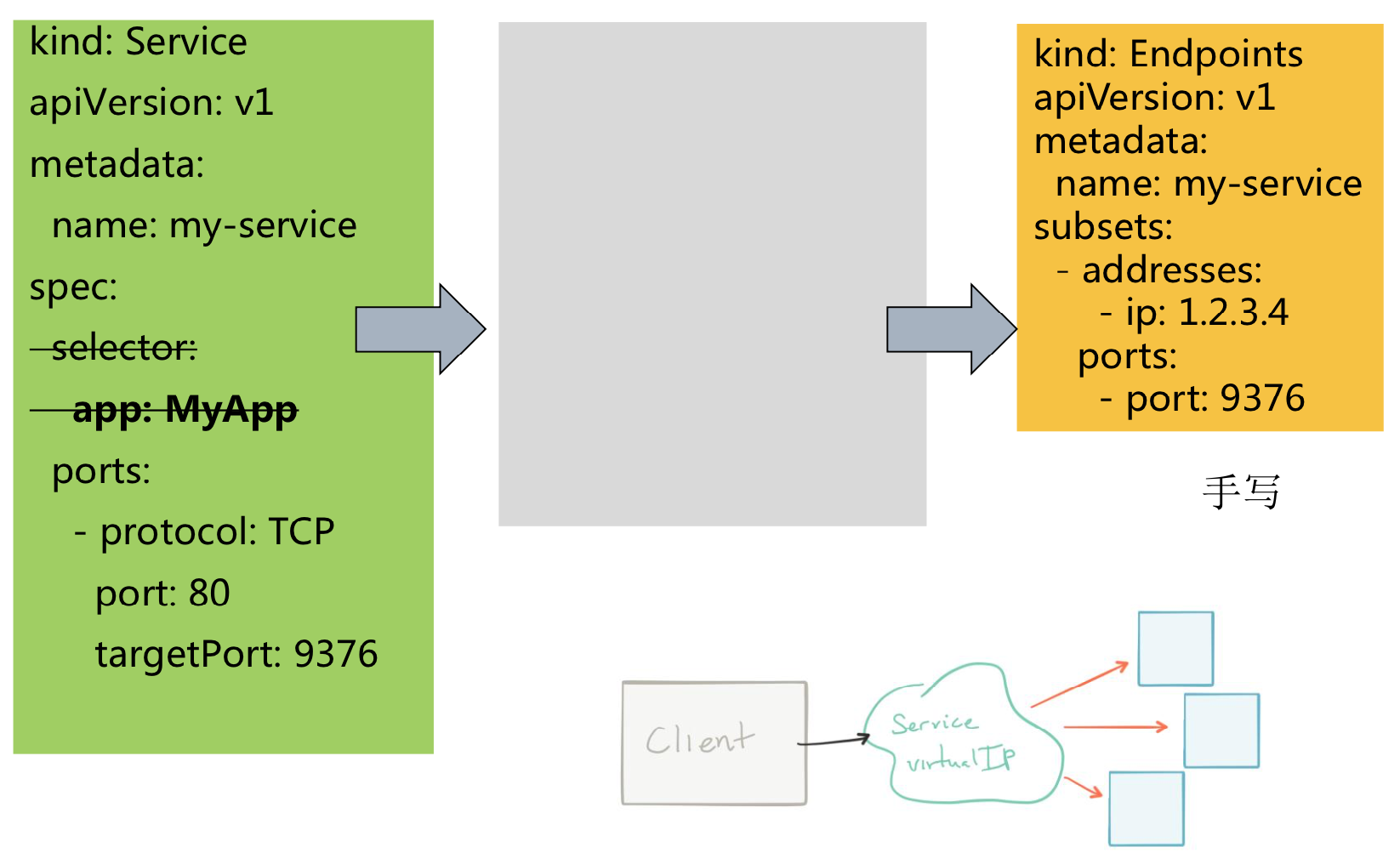
Services → Headless Services
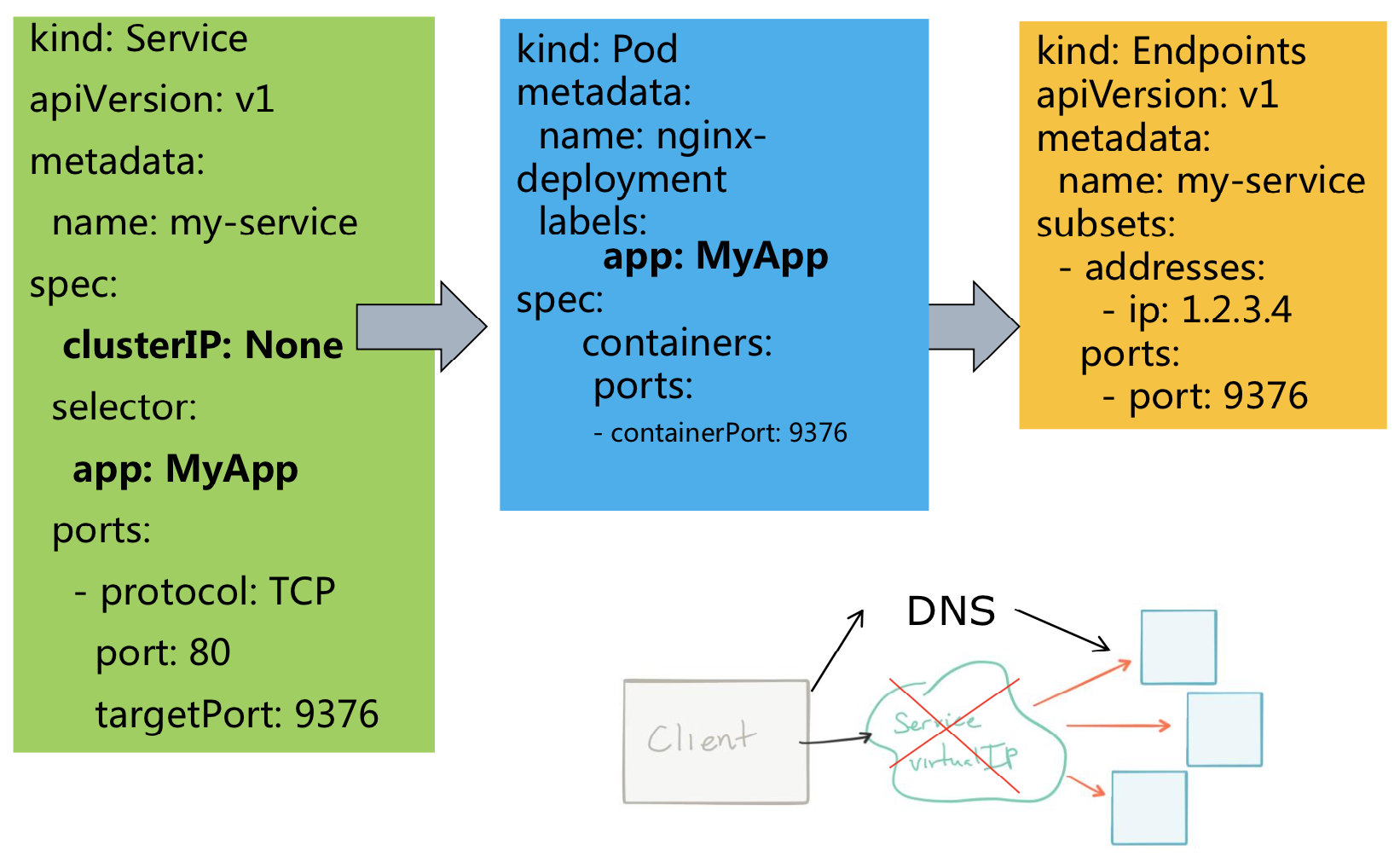
Services → Headless Services → 无Selector
服务发现:DNS
- 一个可选(尽管强烈推荐)集群插件 是 DNS 服务器。 DNS 服务器监视着创建新 Service 的 Kubernetes API,从而为每一 个 Service 创建一组 DNS 记录。 如果整个集群的 DNS 一直被 启用,那么所有的 Pod应该能够自动对 Service 进行名称解析 。
- 例如,有一个名称为 “my-service” 的 Service,它在 Kubernetes 集群中名为 “my-ns” 的 Namespace中,为 “my-service.my-
ns” 创建了一条 DNS 记录。 在名称为 “my-
ns” 的 Namespace 中的 Pod 应该能够简单地通过名称查询找 到 “my-service”。 在另一个 Namespace 中的 Pod 必须限定名 称为 “my-service.my-ns”。 这些名称查询的结果是 Cluster IP。 - Kubernetes 也支持对端口名称的 DNS SRV(Service)记录。 如果名称为 “my-service.my-ns” 的 Service 有一个名为 “http” 的 TCP 端口,可以对 “_http._tcp.my-service.my-ns” 执行 DNS SRV 查询,得到 “http” 的端口号。
DaemonSet
DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本。当有 Node 加入集群时,也会为他们新增一个 Pod 。当有 Node 从集群移除时 ,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph。
在每个 Node 上运行日志收集 daemon,例如fluentd、logstash。
在每个 Node 上运行监控 daemon,例如 Prometheus Node Exporter、
collectd、Datadog 代理、New Relic 代理,或 Ganglia gmond。
| DaemonSet | ReplicaSet/Deployment |
|---|---|
| 默认为每个Node上运行 | 不绑定Node,只保持指定个数 |
| >1.6后自身支持滚动升级 | 通过Deployment支持滚动升级 |
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Job Spec格式
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
.spec.completions标志Job结束需要成功运行的Pod个数,默认为1.spec.parallelism标志并行运行的Pod的个数,默认为1spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试例子:
1 | apiVersion: batch/v1 |
CronJob
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
一个 CronJob 对象类似于 crontab (cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 Cron 。
扩展阅读: 瓜子云任务调度系统
CronJob Spec
.spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron.spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job.spec.startingDeadlineSeconds:启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限.spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:Allow(默认):允许并发运行 JobForbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个Replace:取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
.spec.suspend:挂起,该字段也是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为false。.spec.successfulJobsHistoryLimit和.spec.failedJobsHistoryLimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认没有限制,所有成功和失败的 Job 都会被保留。然而,当运行一个 Cron Job 时,Job 可以很快就堆积很多,推荐设置这两个字段的值。设置限制的值为
0,相关类型的 Job 完成后将不会被保留。
1 | apiVersion: batch/v2alpha1 |
Cron Job 限制
Cron Job 在每次调度运行时间内 大概 会创建一个 Job 对象。我们之所以说 大概 ,是因为在特定的环境下可能会创建两个 Job,或者一个 Job 都没创建。我们尝试少发生这种情况,但却不能完全避免。因此,创建 Job 操作应该是 幂等的。
Job 根据它所创建的 Pod 的并行度,负责重试创建 Pod,并就决定这一组 Pod 的成功或失败。Cron Job 根本就不会去检查 Pod。
Volume
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次,在 Pod 中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的 Volume抽象就很好的解决了这些问题。
背景
Docker 中也有一个 volume 的概念,尽管它稍微宽松一些,管理也很少。在 Docker 中,卷就像是磁盘或是另一个容器中的一个目录。它的生命周期不受管理,直到最近才有了 local-disk-backed 卷。Docker 现在提供了卷驱动程序,但是功能还非常有限(例如Docker1.7只允许每个容器使用一个卷驱动,并且无法给卷传递参数)。
另一方面,Kubernetes 中的卷有明确的寿命——与封装它的 Pod 相同。所以,卷的生命比 Pod 中的所有容器都长,当这个容器重启时数据仍然得以保存。当然,当 Pod 不再存在时,卷也将不复存在。也许更重要的是,Kubernetes 支持多种类型的卷,Pod 可以同时使用任意数量的卷。
卷的核心是目录,可能还包含了一些数据,可以通过 pod 中的容器来访问。该目录是如何形成的、支持该目录的介质以及其内容取决于所使用的特定卷类型。
要使用卷,需要为 pod 指定为卷(spec.volumes 字段)以及将它挂载到容器的位置(spec.containers.volumeMounts 字段)。
容器中的进程看到的是由其 Docker 镜像和卷组成的文件系统视图。 Docker 镜像位于文件系统层次结构的根目录,任何卷都被挂载在镜像的指定路径中。卷无法挂载到其他卷上或与其他卷有硬连接。Pod 中的每个容器都必须独立指定每个卷的挂载位置。
卷的类型
Kubernetes 支持以下类型的卷:
| 卷类型 | 说明 | 分类 |
|---|---|---|
| awsElasticBlockStore | 亚马逊块存储 | 云盘 |
| azureDisk | 微软azure DataDisk,单机挂载 | 云盘 |
| azureFile | 微软azure File,可多机挂载 | 云盘 |
| cephfs | 红帽推出的软件分布式存储 |
分布式存储 |
| csi | 建立一个行业标准接口的规范 |
接口 |
| downwardAPI | 从Pod元数据生成文件 | k8s元数据 |
| emptyDir | 空白目录,在node上开辟的临时空间 | 本地盘 |
| fc (fibre channel) | 光纤通道 | 远程存储 |
| flocker | 第三方平台,已倒闭 | 平台 |
| gcePersistentDisk | 谷歌远程盘,一写多读 | 云盘 |
| gitRepo | Git仓库远程下载,无认证能力 | 版本控制 |
| glusterfs | 另一种红帽推出的软分布式存储 |
分布式存储 |
| 卷类型 | 说明 | 分类 |
|---|---|---|
| hostPath | 本机node节点路径,长期保存 | 本地盘 |
| iscsi | iSCSI(SCSI over IP)卷 | 远程存储 |
| local | 将本地盘划为PV,Pod自动调度过来 | 本地盘 |
| nfs | NFS远程存储 | 远程存储 |
| persistentVolumeClaim | 按需创建远程盘 | 接口 |
| projected | 把secret,downwardAPI,configMap放同个目录下 | k8s元数据 |
| portworxVolume | 部署在k8s上的分布式存储,不成熟 | 分布式存储 |
| quobyte | 一种小众的云存储方案 | 远程存储 |
| rbd | Ceph’s RADOS Block Devices,块设备 | 分布式存储 |
| scaleIO | EMC的存储方案 | 远程存储 |
| secret | K8s的secret对象 | k8s元数据 |
| storageos | 容器存储方案 | 分布式存储 |
| vsphereVolume | Vmware存储卷 | 云盘 |
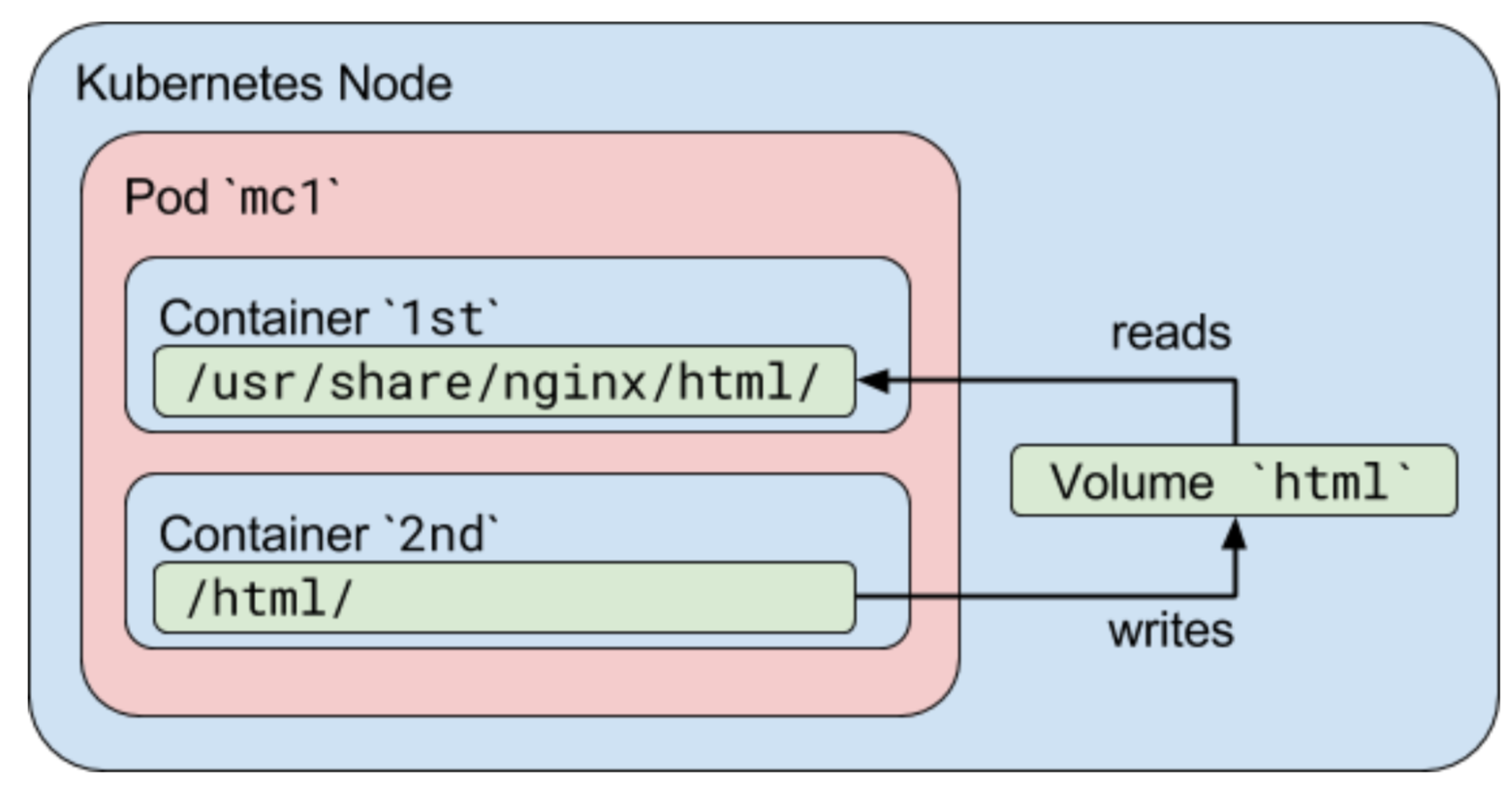
这里以emptyDir为例,当 Pod 被分配给节点时,首先创建 emptyDir 卷,并且只要该 Pod 在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。Pod 中的容器可以读取和写入 emptyDir 卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir 中的数据将被永久删除。
注意:容器崩溃不会从节点中移除 pod,因此 emptyDir 卷中的数据在容器崩溃时是安全的。
emptyDir 的用法有:
- 暂存空间,例如用于基于磁盘的合并排序
- 用作长时间计算崩溃恢复时的检查点
Web服务器容器提供数据时,保存内容管理器容器提取的文件
Pod示例:
1 | apiVersion: v1 |
- Volume -> volumeMounts对应
- 通过名称对应
- 1:n对应,在多个容器里面同时挂载
区分emptyDir与hostPath
| emptyDir | hostPath |
|---|---|
| 生命周期 = Pod | 生命周期 = Node |
| 不能指定路径 | 指定路径 |
| 同Pod的多容器间可共 享 | 同Pod的多容器 同Node的多Pod |
ConfigMap - k8s的应用配置解决方案
其实ConfigMap功能在Kubernetes1.2版本的时候就有了,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。这些配置信息需要与docker image解耦,你总不能每修改一个配置就重做一个image吧?ConfigMap API给我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制大对象。
概览
ConfigMap API资源用来保存key-value pair配置数据,这个数据可以在pods里使用,或者被用来为像controller一样的系统组件存储配置数据。虽然ConfigMap跟Secrets类似,但是ConfigMap更方便的处理不含敏感信息的字符串。 注意:ConfigMaps不是属性配置文件的替代品。ConfigMaps只是作为多个properties文件的引用。你可以把它理解为Linux系统中的/etc目录,专门用来存储配置文件的目录。下面举个例子,使用ConfigMap配置来创建Kuberntes Volumes,ConfigMap中的每个data项都会成为一个新文件。
1 | kind: ConfigMap |
data一栏包括了配置数据,ConfigMap可以被用来保存单个属性,也可以用来保存一个配置文件。 配置数据可以通过很多种方式在Pods里被使用。ConfigMaps可以被用来:
- 设置环境变量的值
- 在容器里设置命令行参数
- 在数据卷里面创建config文件
用户和系统组件两者都可以在ConfigMap里面存储配置数据。
Secret
Secret解决了密码、token、密钥等敏感数据的配置问题,而不需要把这些敏感数据暴露到镜像或者Pod Spec中。Secret可以以Volume或者环境变量的方式使用。
Secret有三种类型:
- Service Account :用来访问Kubernetes API,由Kubernetes自动创建,并且会自动挂载到Pod的
/run/secrets/kubernetes.io/serviceaccount目录中; - Opaque :base64编码格式的Secret,用来存储密码、密钥等;
- kubernetes.io/dockerconfigjson :用来存储私有docker registry的认证信息。
Opaque Secret
Opaque类型的数据是一个map类型,要求value是base64编码格式:
1 | $ echo -n "admin" | base64 |
secrets.yml
1 | apiVersion: v1 |
接着,就可以创建secret了:kubectl create -f secrets.yml。
创建好secret之后,有两种方式来使用它:
- 以Volume方式
- 以环境变量方式
将Secret挂载到Volume中
1 | apiVersion: v1 |
将Secret导出到环境变量中
1 | apiVersion: extensions/v1beta1 |
Secret更多详细信息:Secret
Persistent Volume(持久化卷)
对于管理计算资源来说,管理存储资源明显是另一个问题。PersistentVolume 子系统为用户和管理员提供了一个 API,该 API 将如何提供存储的细节抽象了出来。为此,我们引入两个新的 API 资源:PersistentVolume 和 PersistentVolumeClaim。
PersistentVolume(PV)是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是 Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。此 API 对象包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统。
PersistentVolumeClaim(PVC)是用户存储的请求。它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或 只读多次模式挂载)。
虽然 PersistentVolumeClaims 允许用户使用抽象存储资源,但用户需要具有不同性质(例如性能)的 PersistentVolume 来解决不同的问题。集群管理员需要能够提供各种各样的 PersistentVolume,这些PersistentVolume 的大小和访问模式可以各有不同,但不需要向用户公开实现这些卷的细节。对于这些需求,StorageClass 资源可以实现。
更多详细内容详见:PV
绑定块卷
如果用户通过使用 PersistentVolumeClaim 规范中的 volumeMode 字段指示此请求来请求原始块卷,则绑定规则与以前不认为该模式为规范一部分的版本略有不同。
下面是用户和管理员指定请求原始块设备的可能组合的表格。该表指示卷是否将被绑定或未给定组合。静态设置的卷的卷绑定矩阵:
| PV volumeMode | PVC volumeMode | 结果 |
|---|---|---|
| unspecified | unspecified | 绑定 |
| unspecified | Block | 不绑定 |
| unspecified | Filesystem | 绑定 |
| Block | unspecified | 不绑定 |
| Block | Block | 绑定 |
| Block | Filesystem | 不绑定 |
| Filesystem | Filesystem | 绑定 |
| Filesystem | Block | 不绑定 |
| Filesystem | unspecified | 绑定 |
Namespace
在一个Kubernetes集群中可以使用namespace创建多个“虚拟集群”,这些namespace之间可以完全隔离,也可以通过某种方式,让一个namespace中的service可以访问到其他的namespace中的服务,我们在CentOS中部署kubernetes1.6集群的时候就用到了好几个跨越namespace的服务,比如Traefik ingress和kube-systemnamespace下的service就可以为整个集群提供服务,这些都需要通过RBAC定义集群级别的角色来实现。
哪些情况下适合使用多个namespace
因为namespace可以提供独立的命名空间,因此可以实现部分的环境隔离。当你的项目和人员众多的时候可以考虑根据项目属性,例如生产、测试、开发划分不同的namespace。
Namespace使用
获取集群中有哪些namespace
1 | kubectl get ns |
集群中默认会有default和kube-system这两个namespace。
在执行kubectl命令时可以使用-n指定操作的namespace。
用户的普通应用默认是在default下,与集群管理相关的为整个集群提供服务的应用一般部署在kube-system的namespace下,例如我们在安装kubernetes集群时部署的kubedns、heapseter、EFK等都是在这个namespace下面。
另外,并不是所有的资源对象都会对应namespace,node和persistentVolume就不属于任何namespace。
K8S调度机制

- 预选 : 根据配置的 Predicates Policies(默认为 DefaultProvider 中定义的 default predicates policies 集合)过滤掉那些不满足 Policies的的Nodes,剩下的Nodes作为优选的输入。
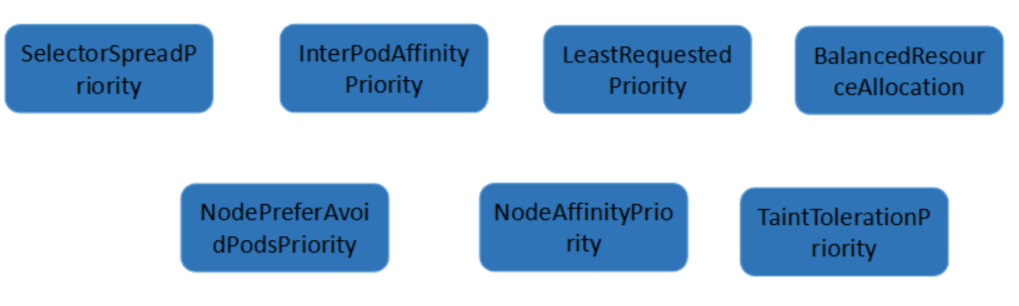
- 优选 : 根据配置的 Priorities Policies(默认为 DefaultProvider 中定义的 default priorities policies 集合)给预选后的Nodes进 行打分排名,得分最高的Node即作为最适合的Node,该Pod 就Bind到这个Node。
预选
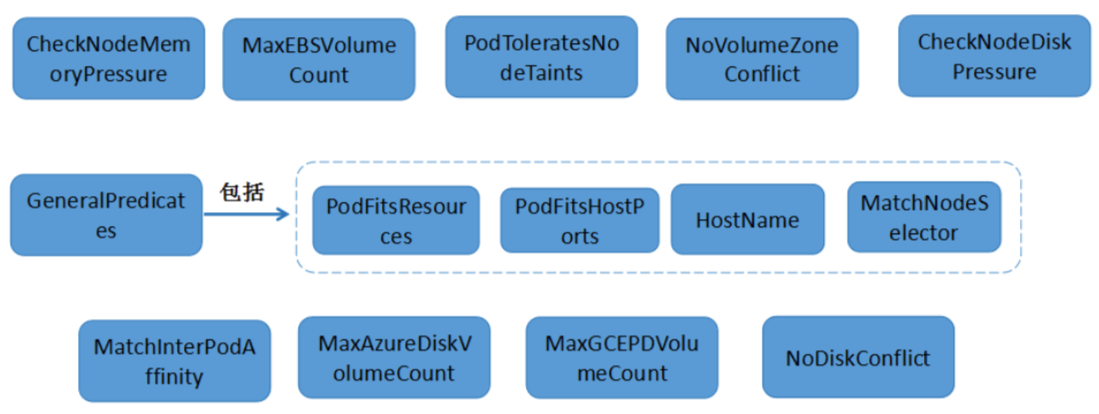
- 系统当中有10个node,只有3台有GPU
- 希望3个pod部署到这3个node上去
- 当有GPU的机器扩容时,希望动态增加pod
优选
亲和/反亲和
| 亲和 | 反亲和 |
|---|---|
| 传统应用进行容器化, 拆分微服务之后的部 署约束,需要按实例 逐一配对就近部署, 容器间通信就近路由, 减少网络消耗。 | 高可靠性考虑,同个 应用的多个实例反亲 和部署,减少宕机影 响 互相干扰的应用反亲 和部署,避免干扰。 |
K8S网络
Docker的网络模型

其中:
- 容器—虚拟网卡—tup设备—网桥—宿主机协议栈—宿主机网卡
- 容器访问宿主机网络通过SNAT
- 容器绑定宿主机端口,被外部访问,通过DNAT
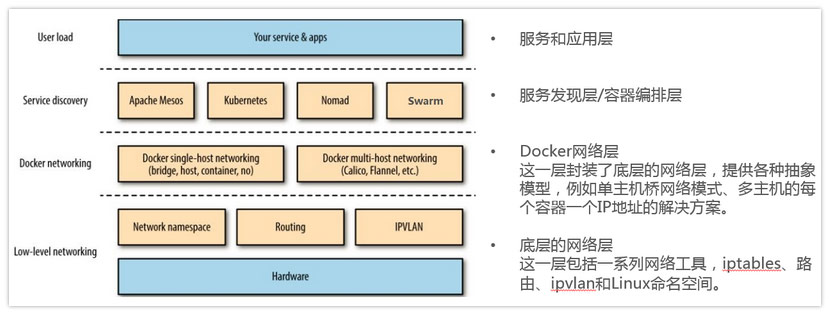
K8S网络模型
设计理念
- 所有容器不使用 NAT 就可以互相通信(这跟 Docker 的默认实现是不同的);
- 所有节点跟容器之间不使用 NAT 就可以互相通信;
- 容器自己看到的地址,跟其他人访问自己使用的地址应 该是一样的(其实还是在说不要有 NAT)。
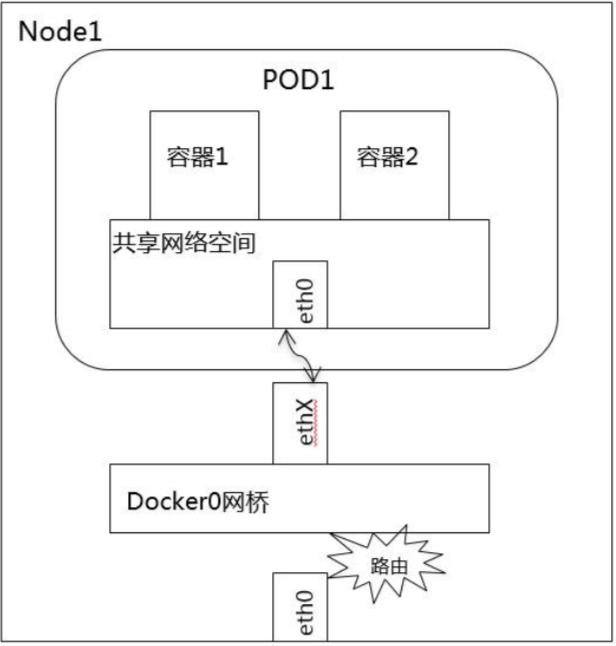
Pod 内部
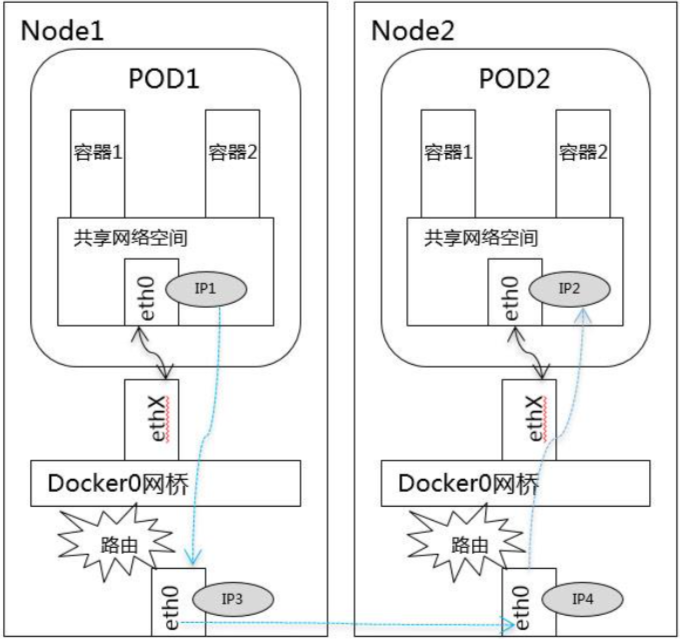
不同节点pod
容器网络方案
| 方案 | 典型实现 |
|---|---|
| 隧道方案 ( Overlay Networking ) | Flannel:UDP广播,VxLan |
| Weave:UDP广播,本机建立新的BR,通过PCAP互通 | |
| Open vSwitch(OVS):基于VxLan和GRE协议,但是 性能方面损失比较严重 | |
| Racher:IPsec | |
| 路由方案 (Underlay Networking) | Calico:基于BGP协议的路由方案,支持很细致的ACL 控制,对混合云亲和度比较高。 |
| Macvlan:从逻辑和Kernel层来看隔离性和性能最优的 方案,基于二层隔离,所以需要二层路由器支持,大多 数云服务商不支持,所以混合云上比较难以实现。 |
Flannel
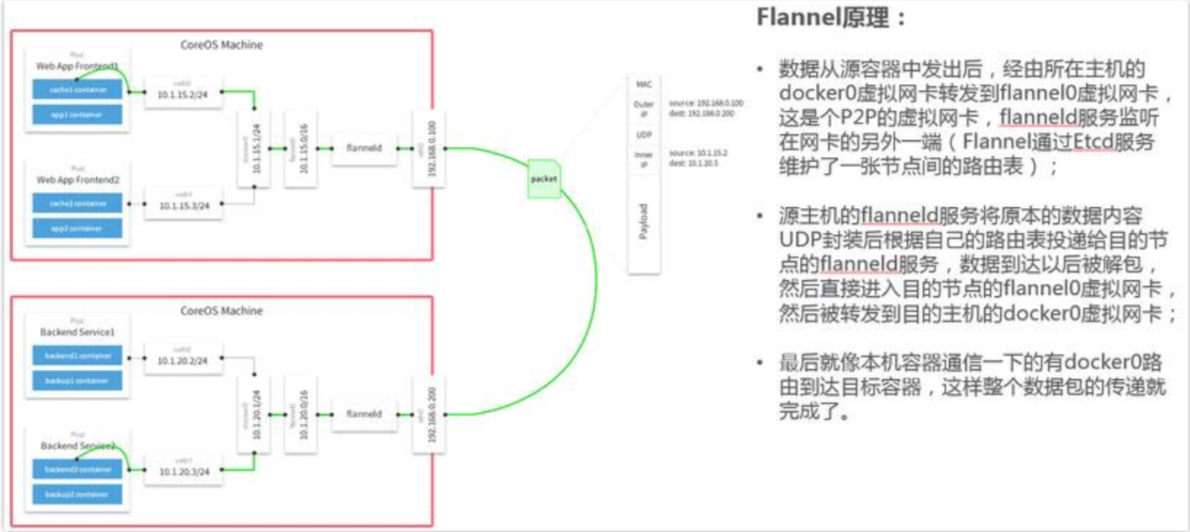
- Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来 说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集 群唯一的虚拟IP地址。
- 在默认的Docker配置中,每个节点上的Docker服务会分别负责所在节点 容器的IP分配。这样导致的一个问题是,不同节点上容器可能获得相同 的内外IP地址。并使这些容器之间能够之间通过IP地址相互找到,也就 是相互ping通。
- Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则 ,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的 ”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信。
- Flannel实质上是一种“覆盖网络(overlaynetwork)”,也就是将TCP数据包 装在另一种网络包里面进行路由转发和通信,目前已经支持udp、vxlan 、host-gw、aws-vpc、gce和alloc路由等数据转发方式,默认的节点间数 据通信方式是UDP转发。
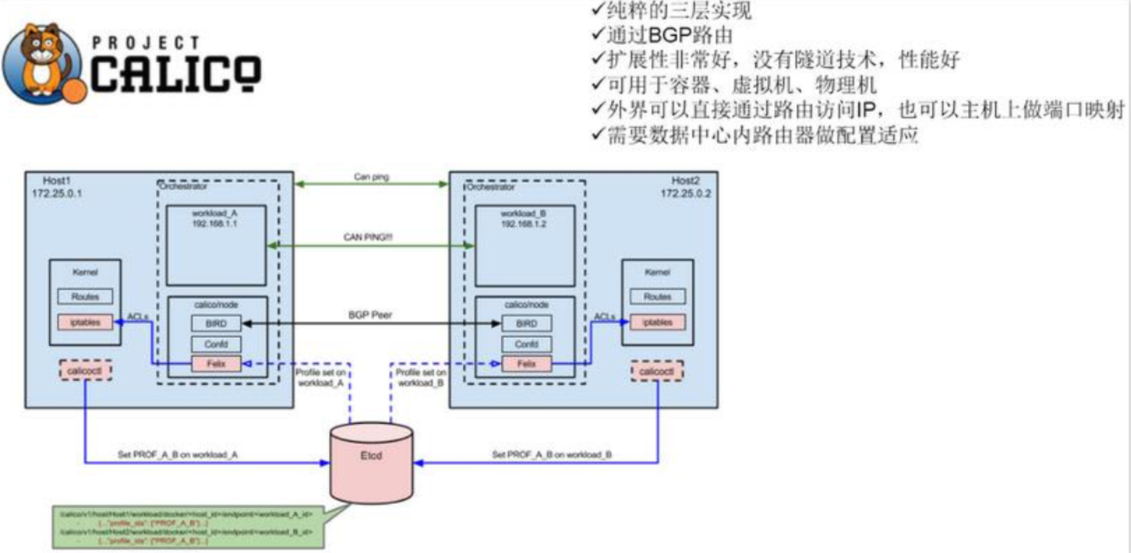
Calico
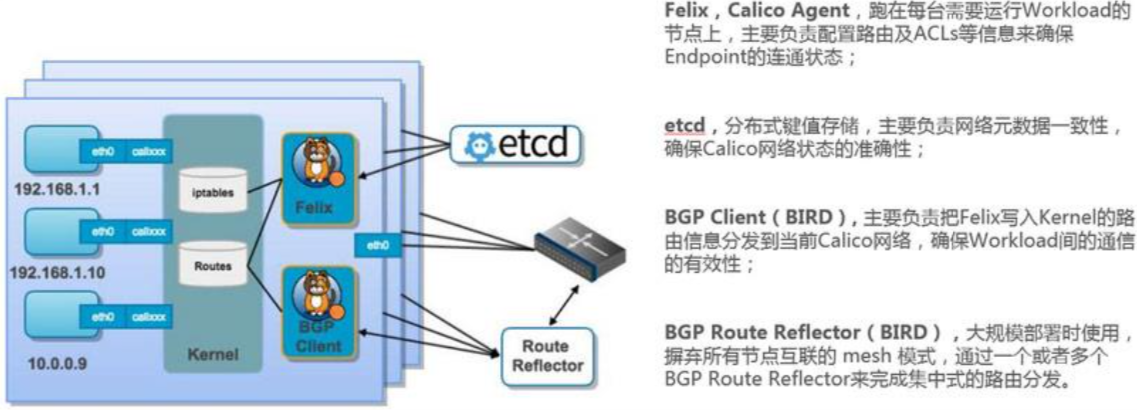
Calico是一个纯3层的数据中心网络方案,而且无缝集成像OpenStack 这种IaaS云架构,能够提供可控的VM、容器、裸机之间的IP通信。 Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一 个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通 过BGP协议传播可达信息(路由)到剩余数据中心。
Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter 来负责数据转发,而每个vRouter通过BGP协议负责把自己上运行的 workload的路由信息像整个Calico网络内传播——小规模部署可以直 接互联,大规模下可通过指定的BGP route reflector来完成。
Calico节点组网可以直接利用数据中心的网络结构(无论是L2或者 L3),不需要额外的NAT,隧道或者Overlay Network。
- Calico基于iptables还提供了丰富而灵活的网络Policy,保证通过各个 节点上的ACLs来提供Workload的多租户隔离、安全组以及其他可达 性限制等功能。
calico特性
网络性能对比
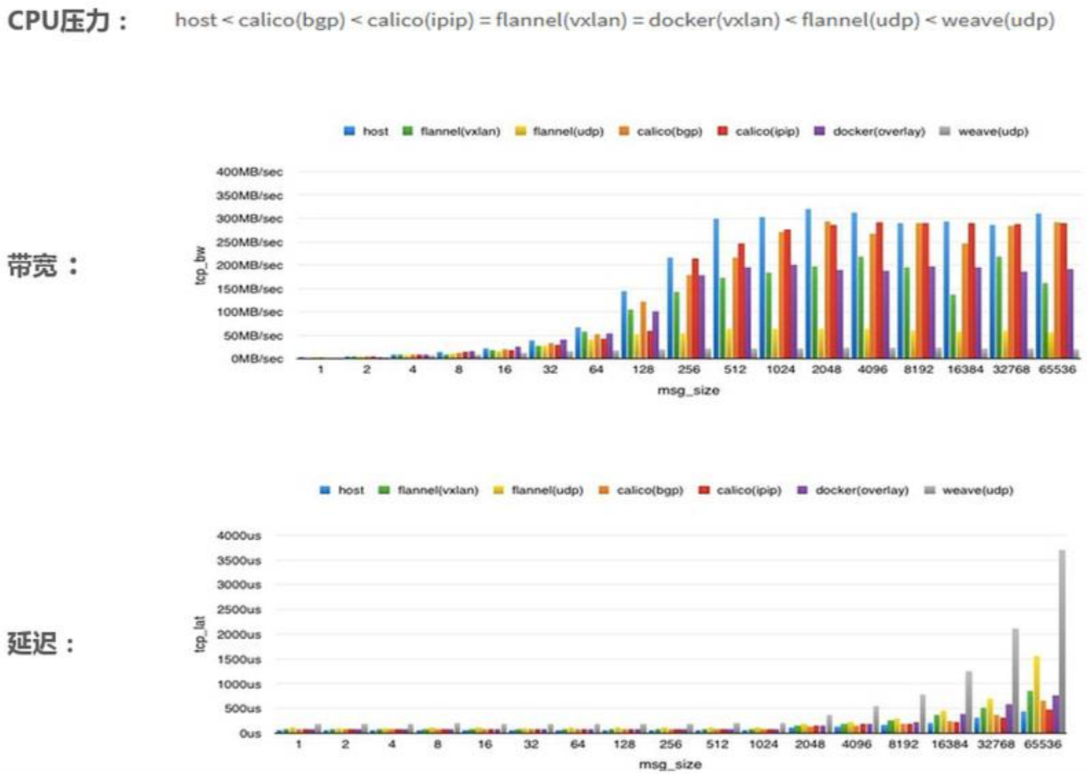
网络方案总结
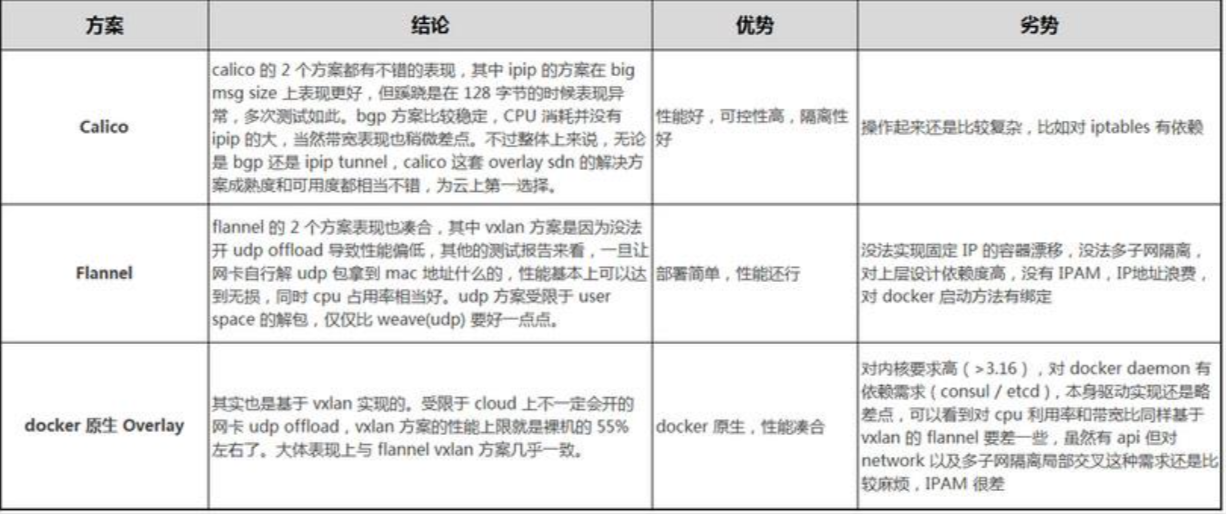
CNI vs CNM
CNI
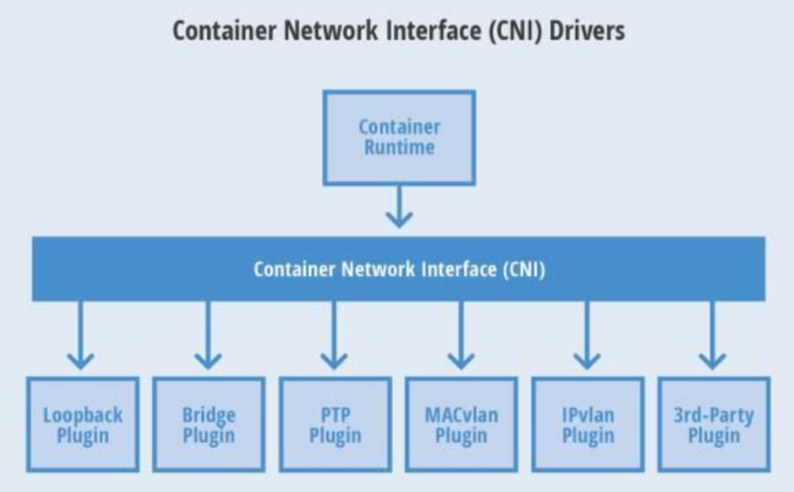
CNI ADD/DELETE
CNI的接口设计的非常简洁,只有两个接口ADD/DELETE。 以 ADD接口为例
Add container to network 参数主要包括:
- Version. CNI版本号
- Container ID. 这是一个可选的参数,提供容器的id
- Network namespace path. 容器的命名空间的路径,比如 /proc/[pid]/ns/net
- Network configuration. 这是一个json的文档,具体可以参看network-configuration
- Extra arguments. 其他参数
Name of the interface inside the container. 容器内的网卡名 返回值:
IPs assigned to the interface. ipv4或者ipv6地址
- DNS information. DNS相关信息
Server: KubeProxy
VIP与Service代理
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式。 在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是 iptables 代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。
在 Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
iptables代理模式
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 clusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 backend 中的某个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 backend Pod。
默认的策略是,随机选择一个 backend。 实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
和 userspace 代理类似,网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。 这应该比 userspace 代理更快、更可靠。然而,不像 userspace 代理,如果初始选择的 Pod 没有响应,iptables 代理不能自动地重试另一个 Pod,所以它需要依赖 readiness probes。
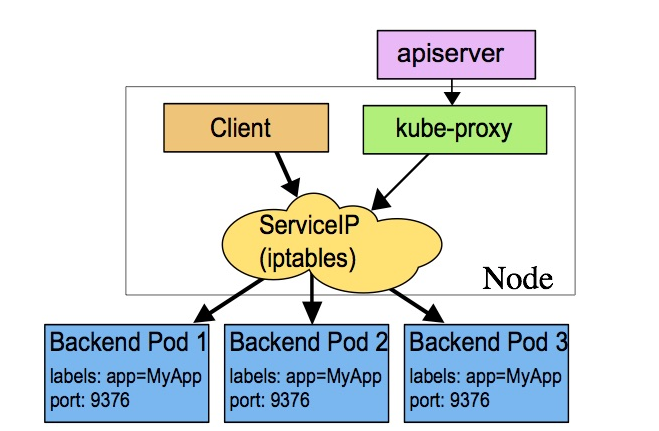
ipvs代理模式
这种模式,kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度lc:最小连接数dh:目标哈希sh:源哈希sed:最短期望延迟nq: 不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
Kube-DNS
推荐阅读:kube-dns前世今生
Ingress
通常情况下,service和pod仅可在集群内部网络中通过IP地址访问。所有到达边界路由器的流量或被丢弃或被转发到其他地方。从概念上讲,可能像下面这样:
1 | internet |
Ingress是授权入站连接到达集群服务的规则集合。
1 | internet |
你可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等。用户通过POST Ingress资源到API server的方式来请求ingress。 Ingress controller负责实现Ingress,通常使用负载平衡器,它还可以配置边界路由和其他前端,这有助于以HA方式处理流量。
Ingress类型
单Service Ingress
Kubernetes中已经存在一些概念可以暴露单个service(查看替代方案),但是你仍然可以通过Ingress来实现,通过指定一个没有rule的默认backend的方式。
ingress.yaml定义文件:
1 | apiVersion: extensions/v1beta1 |
使用kubectl create -f命令创建,然后查看ingress:
1 | $ kubectl get ing |
107.178.254.228就是Ingress controller为了实现Ingress而分配的IP地址。RULE列表示所有发送给该IP的流量都被转发到了BACKEND所列的Kubernetes service上。
简单展开
如前面描述的那样,kubernete pod中的IP只在集群网络内部可见,我们需要在边界设置一个东西,让它能够接收ingress的流量并将它们转发到正确的端点上。这个东西一般是高可用的loadbalancer。使用Ingress能够允许你将loadbalancer的个数降低到最少,例如,假如你想要创建这样的一个设置:
1 | foo.bar.com -> 178.91.123.132 -> / foo s1:80 |
你需要一个这样的ingress:
1 | apiVersion: extensions/v1beta1 |
使用kubectl create -f创建完ingress后:
1 | $ kubectl get ing |
只要服务(s1,s2)存在,Ingress controller就会将提供一个满足该Ingress的特定loadbalancer实现。 这一步完成后,您将在Ingress的最后一列看到loadbalancer的地址。
K8S 集群与监控
cAdvisor
cAdvisor其实就是如果你运行docker stats -all命令所获得 的信息的图形化版本
单容器运行:
1 | docker run \ |
Heapster
方案架构图
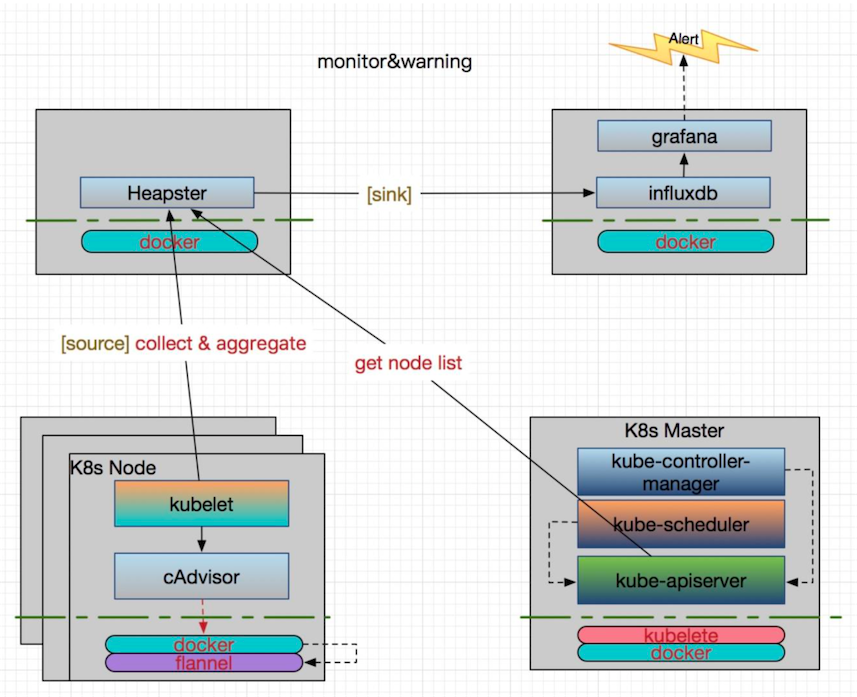
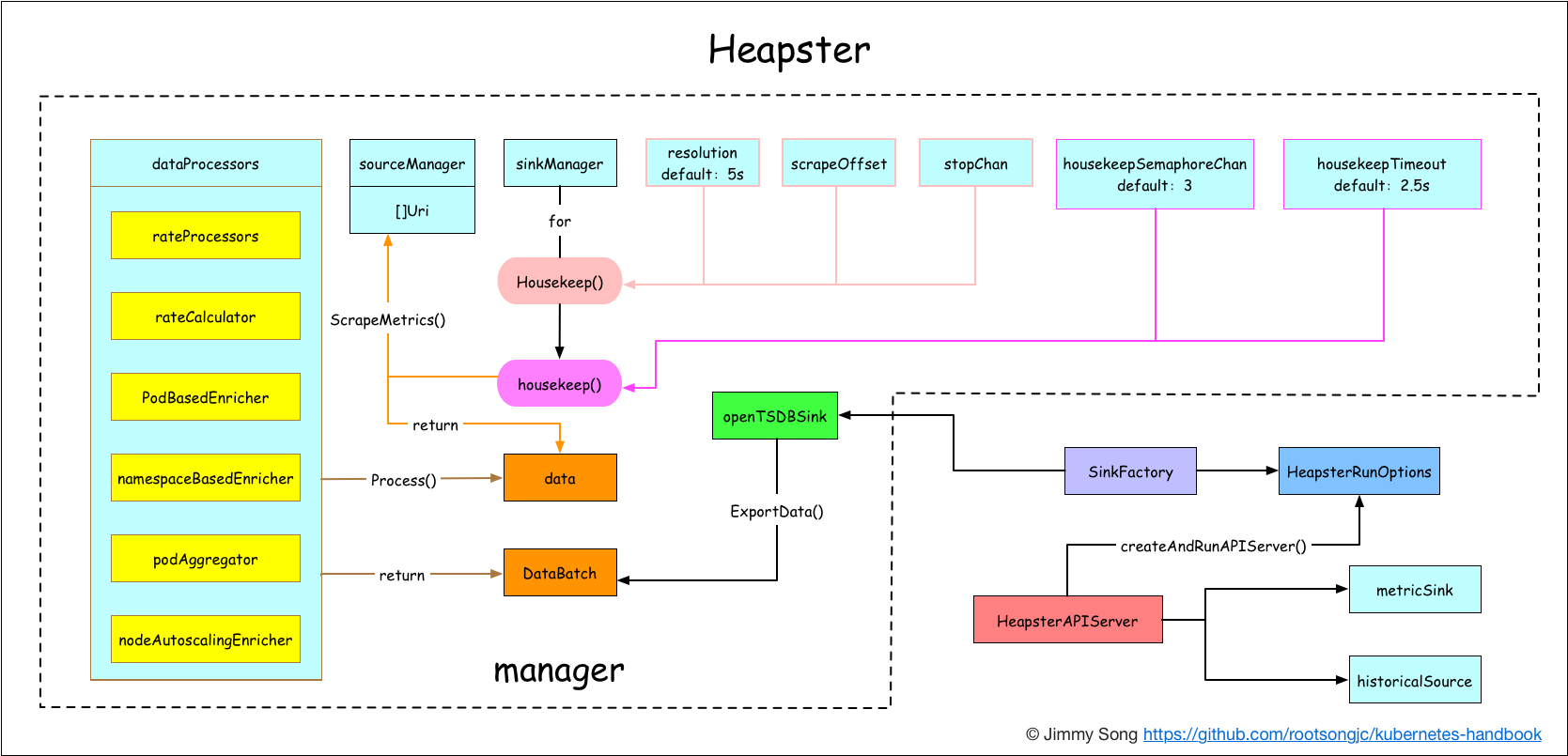
Heapster作为kubernetes安装过程中默认安装的一个插件,见安装heapster插件。这对于集群监控十分有用,同时在Horizontal Pod Autoscaling中也用到了,HPA将Heapster作为Resource Metrics API,向其获取metric,做法是在kube-controller-manager 中配置--api-server指向kube-aggregator,也可以使用heapster来实现,通过在启动heapster的时候指定--api-server=true。
Heapster可以收集Node节点上的cAdvisor数据,还可以按照kubernetes的资源类型来集合资源,比如Pod、Namespace域,可以分别获取它们的CPU、内存、网络和磁盘的metric。默认的metric数据聚合时间间隔是1分钟。
Kubernetes 1.11 不建议使用 Heapster ,就 Sig Instrumentation 而言,这是为了转向新的Kubernetes 监控模型的持续努力的一部分。仍应使用 Heapster 进行自动扩展的群集应迁移到metrics-server和自定义指标API。有关详细信息,请参阅 Kubernetes 1.11 版本日志。
Prometheus
架构图

Prometheus 是由 SoundCloud 开源监控告警解决方案,从 2012 年开始编写代码,再到 2015 年 github 上开源以来,已经吸引了 9k+ 关注,以及很多大公司的使用;2016 年 Prometheus 成为继 k8s 后,第二名 CNCF(Cloud Native Computing Foundation) 成员。
作为新一代开源解决方案,很多理念与 Google SRE 运维之道不谋而合。
主要功能
- 多维 数据模型(时序由 metric 名字和 k/v 的 labels 构成)。
- 灵活的查询语句(PromQL)。
- 无依赖存储,支持 local 和 remote 不同模型。
- 采用 http 协议,使用 pull 模式,拉取数据,简单易懂。
- 监控目标,可以采用服务发现或静态配置的方式。
- 支持多种统计数据模型,图形化友好。
核心组件
- Prometheus Server, 主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理。
- client libraries,用于对接 Prometheus Server, 可以查询和上报数据。
- push gateway ,用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。
- 各种汇报数据的 exporters ,例如汇报机器数据的 node_exporter, 汇报 MongoDB 信息的 MongoDB exporter 等等。
- 用于告警通知管理的 alertmanager 。
详细部署请参阅超哥的使用Prometheus监控kubernetes集群
身份与权限认证
Kubernetes中提供了良好的多租户认证管理机制,如RBAC、ServiceAccount还有各种Policy等。
Service Account
Service Account为Pod中的进程提供身份信息。
当您(真人用户)访问集群(例如使用kubectl命令)时,apiserver 会将您认证为一个特定的 User Account(目前通常是admin,除非您的系统管理员自定义了集群配置)。Pod 容器中的进程也可以与 apiserver 联系。 当它们在联系 apiserver 的时候,它们会被认证为一个特定的 Service Account(例如default)。
当您创建 pod 的时候,如果您没有指定一个 service account,系统会自动得在与该pod 相同的 namespace 下为其指派一个default service account。如果您获取刚创建的 pod 的原始 json 或 yaml 信息(例如使用kubectl get pods/podename -o yaml命令),您将看到spec.serviceAccountName字段已经被设置为 default。
您可以在 pod 中使用自动挂载的 service account 凭证来访问 API,如 Accessing the Cluster 中所描述。
Service account 是否能够取得访问 API 的许可取决于您使用的 授权插件和策略。
在 1.6 以上版本中,您可以选择取消为 service account 自动挂载 API 凭证,只需在 service account 中设置 automountServiceAccountToken: false:
1 | apiVersion: v1 |
在 1.6 以上版本中,您也可以选择只取消单个 pod 的 API 凭证自动挂载:
1 | apiVersion: v1 |
如果在 pod 和 service account 中同时设置了 automountServiceAccountToken , pod 设置中的优先级更高。
User Account & Service Account 区别
| User Account | Service Account |
|---|---|
| 为人设计,为客户端设计 (kubectl/kubelet/controller/sc heduler) | 为Pod中的进程调用k8s API 设计 |
| 跨namespace | 仅当前namespace |
| .kube/config | Kubectl get servcieaccount Kubectl get secret |
| 《Kubernetes集群安全配置 案例》 《Kubernetes 认证》 | 《名词解释:Service Account》 |
RBAC——基于角色的访问控制
API概述
本节将介绍RBAC API所定义的四种顶级类型。用户可以像使用其他Kubernetes API资源一样 (例如通过kubectl、API调用等)与这些资源进行交互。例如,命令kubectl create -f (resource).yml 可以被用于以下所有的例子,当然,读者在尝试前可能需要先阅读以下相关章节的内容。
Role与ClusterRole
在RBAC API中,一个角色包含了一套表示一组权限的规则。 权限以纯粹的累加形式累积(没有”否定”的规则)。 角色可以由命名空间(namespace)内的Role对象定义,而整个Kubernetes集群范围内有效的角色则通过ClusterRole对象实现。
一个Role对象只能用于授予对某一单一命名空间中资源的访问权限。 以下示例描述了”default”命名空间中的一个Role对象的定义,用于授予对pod的读访问权限:
1 | kind: Role |
ClusterRole对象可以授予与Role对象相同的权限,但由于它们属于集群范围对象, 也可以使用它们授予对以下几种资源的访问权限:
- 集群范围资源(例如节点,即node)
- 非资源类型endpoint(例如”/healthz”)
- 跨所有命名空间的命名空间范围资源(例如pod,需要运行命令
kubectl get pods --all-namespaces来查询集群中所有的pod)
下面示例中的ClusterRole定义可用于授予用户对某一特定命名空间,或者所有命名空间中的secret(取决于其绑定方式)的读访问权限:
1 | kind: ClusterRole |
RoleBinding与ClusterRoleBinding
角色绑定将一个角色中定义的各种权限授予一个或者一组用户。 角色绑定包含了一组相关主体(即subject, 包括用户——User、用户组——Group、或者服务账户——Service Account)以及对被授予角色的引用。 在命名空间中可以通过RoleBinding对象授予权限,而集群范围的权限授予则通过ClusterRoleBinding对象完成。
RoleBinding可以引用在同一命名空间内定义的Role对象。 下面示例中定义的RoleBinding对象在”default”命名空间中将”pod-reader”角色授予用户”jane”。 这一授权将允许用户”jane”从”default”命名空间中读取pod。
1 | # 以下角色绑定定义将允许用户"jane"从"default"命名空间中读取pod。 |
RoleBinding对象也可以引用一个ClusterRole对象用于在RoleBinding所在的命名空间内授予用户对所引用的ClusterRole中 定义的命名空间资源的访问权限。这一点允许管理员在整个集群范围内首先定义一组通用的角色,然后再在不同的命名空间中复用这些角色。
例如,尽管下面示例中的RoleBinding引用的是一个ClusterRole对象,但是用户”dave”(即角色绑定主体)还是只能读取”development” 命名空间中的secret(即RoleBinding所在的命名空间)。
1 | # 以下角色绑定允许用户"dave"读取"development"命名空间中的secret。 |
最后,可以使用ClusterRoleBinding在集群级别和所有命名空间中授予权限。下面示例中所定义的ClusterRoleBinding 允许在用户组”manager”中的任何用户都可以读取集群中任何命名空间中的secret。
1 | # 以下`ClusterRoleBinding`对象允许在用户组"manager"中的任何用户都可以读取集群中任何命名空间中的secret。 |
RBAC——Role VS ClusterRole
| Role: 角色/namespace内 | ClusterRole: 角色/不区分namespace |
|---|---|
| RoleBinding 把role和 [user/serviceAccount/group]关 联起来 | ClusterRoleBinding 把ClusterRole和 [user/serviceAccount/group]关 联起来 |
详细内容详见: RBAC——基于角色的访问控制
k8s技术栈的多租户
