浅谈 Linux 内核中的 Namespace 与 Cgroups
我是在学习 Docker 的时候接触的这两个概念,这两个内核功能也贯穿整个 Docker 容器的运作。那么我们下面简单的谈一谈这两个概念。本章使用自己开发的donkey runtime 与 docker 同步做对比。
Namespace
Namespace 也叫命名空间,是 Linux kernel 的一个功能,以下简称NS,他可以隔离一系列的系统资源,比如 PID、UserID、Network等。在 Docker 中,NS 更多的用于做系统的隔离,比如让不同的用户只能访问自己的服务,让每个容器在自己的 root 的环境下运行自己的程序,使用NS,可以做到 UID 级别的隔离,也就是说以 UID 为 n 的用户,虚拟出来的 NS,可以在自己的 NS 里面拥有 root 权限。但是在真实的物理机器上他还是那个 UID为 n 的用户,并没有 宿主机的 root 权限,这样就解决了用户隔离的问题。
除了 User Namespace,PID也是可以被虚拟的,NS 建立系统的不同视图,从用户角度来看,他拥有自己的 init 进程 (PID == 1),而在外部只是一个普通的进程(PID == N)。
举例说明:
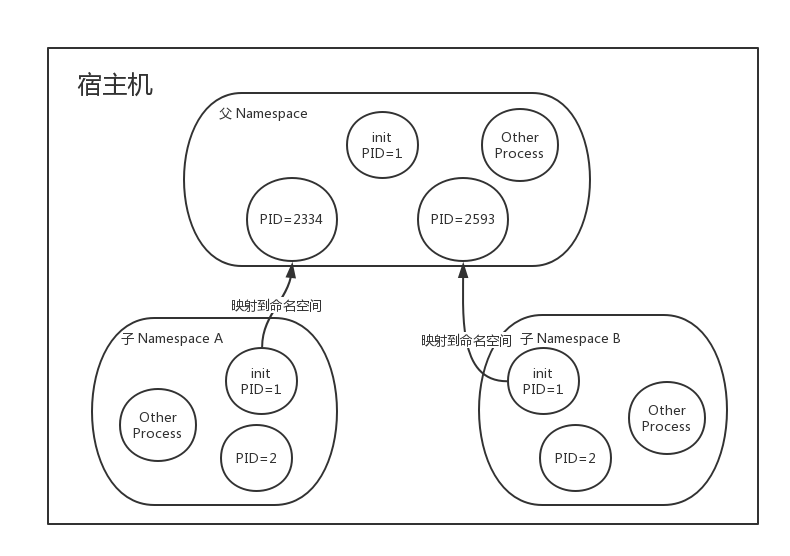
子Namespace A、B 都有自己 PID 为 1 的 init 进程,而它在父 NS 看来只是普通的进程,子NS的进程映射到父 NS 进程上,父 NS 可以知道每个子 NS 的运行状态,而子 NS 之间是隔离的,子 NS 中并不知道 父 NS 中有哪些进程,从上面的关系图可以看出,进程 2334 在父 NS 中的PID为 2334,而在子 NS 中的 PID 为 1。也就是说用户从 NS A中看,它就像 init 进程一样,是自己的初始化进程,而在整个宿主机中,NS A只不过是由PID 2334初始化出来的一个隔离空间而已,同理 PID 2593 也是如此。
当前 Linux 一共实现了 6 种不同类型的 Namespace。
| Namespace 类型 |
系统调用参数 |
内核版本 |
| Mount Namespace |
CLONE_NEWNS |
2.4.19 |
| UTS Namespace |
CLONE_NEWUTS |
2.6.19 |
| IPC Namespace |
CLONE_NEWIPC |
2.6.19 |
| PID Namespace |
CLONE_NEWPID |
2.6.24 |
| Network Namespace |
CLONE_NEWNET |
2.6.29 |
| User Namespace |
CLONE_NEWUSER |
3.8 |
NS 的 API 常用的三个系统调用有:
- clone() 创建新进程
- unshare() 将进程移出某个 NS
- setns() 将进程加入某个 NS
下面就对这几个NS做简单的介绍。
UTS Namespace
它主要用来隔离 nodename 与 domainname 两个系统标识。在 UTS NS 中,每个NS 允许有自己的 hostname。
1
2
3
4
5
6
7
8
9
10
11
| $ hostname
funky-mac
$ docker run -ti --hostname ubuntu123 ubuntu /bin/sh
ubuntu123
$ donkey run -ti --name hello busybox sh
/
/
hello
$ hostname
funky-mac
|
IPC Namespace
它用于隔离 System V IPC 和 POSIX message queues。每一个 IPC NS都有自己的 System V IPC 和 POSIX message queues。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| $ ipcs -q
IPC status from <running system> as of Mon Aug 20 19:00:05 CST 2018
T ID KEY MODE OWNER GROUP
Message Queues:
$ docker run -ti ubuntu bash
root@443da4f613ba:/
------ Message Queues --------
key msqid owner perms used-bytes messages
root@443da4f613ba:/
Message queue id: 0
$ donkey run -ti --name hello busybox sh
/
------ Message Queues --------
key msqid owner perms used-bytes messages
|
PID Namespace
刚刚已经详细讨论了下,他主要用于隔离进程 ID。
1
2
3
4
5
6
7
8
9
10
11
12
| $ echo $$
48123
$ donkey run -ti --name hello busybox sh
echo $$
1
$ docker run -ti ubuntu bash
root@428cf6604a90:/
PID TTY TIME CMD
1 pts/0 00:00:00 bash
12 pts/0 00:00:00 ps
root@428cf6604a90:/
1
|
Mount Namespace
用于隔离各个进程看到的挂载点视图。在不同的 NS 中,看到的文件系统层次是不一样的。在Mount NS中使用mount 与 umount 只会影响当前的 NS,对全局文件系统没有影响。你肯定会想到 chroot,它可以将一个目录变成根节点,Mount NS 不仅仅可以实现这个功能,而且可以更加灵活与安全。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| $ df
Filesystem Size Used Avail Capacity iused ifree %iused Mounted on
/dev/disk1s1 932Gi 152Gi 774Gi 17% 1275908 9223372036853499899 0% /
devfs 193Ki 193Ki 0Bi 100% 666 0 100% /dev
/dev/disk1s4 932Gi 5.5Gi 774Gi 1% 5 9223372036854775802 0% /private/var/vm
map -hosts 0Bi 0Bi 0Bi 100% 0 0 100% /net
map auto_home 0Bi 0Bi 0Bi 100% 0 0 100% /home
/dev/disk1s3 932Gi 495Mi 774Gi 1% 16 9223372036854775791 0% /Volumes/Recovery
$ docker run -ti ubuntu bash
root@428cf6604a90:/
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 59G 3.5G 52G 7% /
tmpfs tmpfs 64M 0 64M 0% /dev
tmpfs tmpfs 1000M 0 1000M 0% /sys/fs/cgroup
/dev/sda1 ext4 59G 3.5G 52G 7% /etc/hosts
shm tmpfs 64M 0 64M 0% /dev/shm
tmpfs tmpfs 1000M 0 1000M 0% /proc/acpi
tmpfs tmpfs 1000M 0 1000M 0% /sys/firmware
$ donkey run -ti --name hello busybox sh
/
Filesystem Type Size Used Available Use% Mounted on
none aufs 39.3G 2.6G 35.1G 7% /
tmpfs tmpfs 244.9M 0 244.9M 0% /dev
|
User Namespace
User NS 主要用于隔离用户的用户组ID,一个进程的 User ID 个 Group IP 在 User NS 内外可以不同。
1
2
3
4
5
6
7
8
9
10
| $ id
uid=501(funky) gid=20(staff)
$ docker run -ti ubuntu bash
root@752b77b90707:/
uid=0(root) gid=0(root) groups=0(root)
$ donkey run -ti --name hello busybox sh
/
uid=0(root) gid=0(root) groups=0(root)
|
Network Namespace
Network NS用于隔离网络设备、IP等网络栈的NS,它可以让每个容器都拥有自己独立的网络设备。并且每个NS 的端口不会互相冲突。在宿主机上搭建网桥后可以很方便的实现容器直接的相互通信。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| $ ifconfig
lo0: flags=8049<UP,LOOPBACK,RUNNING,MULTICAST> mtu 16384
options=1203<RXCSUM,TXCSUM,TXSTATUS,SW_TIMESTAMP>
inet 127.0.0.1 netmask 0xff000000
inet6 ::1 prefixlen 128
inet6 fe80::1%lo0 prefixlen 64 scopeid 0x1
nd6 options=201<PERFORMNUD,DAD>
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
XHC20: flags=0<> mtu 0
XHC1: flags=0<> mtu 0
XHC0: flags=0<> mtu 0
en1: flags=8963<UP,BROADCAST,SMART,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500
options=60<TSO4,TSO6>
ether ca:00:XX
media: autoselect <full-duplex>
status: inactive
$ donkey run -ti --name hello busybox sh
/
/
1: lo: <LOOPBACK> mtu 65536 qdisc noop
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
Cgroups
Linux Cgroups 即 Linux Control Groups,它提供了一组进程以及将来子进程的资源限制、控制和统计能力,这些资源包括CPU、内存、存储等,通过Cgroups,可以方便限制某个进程占用的资源,并且实时监控和统计信息。
Cgroups 三大组件
cgroup 是对进程分组管理的一种机制,一个cgroup包含一组进程,并可以在整个cgroup上增加各种参数配置,将一组进程和一组subsystem的系统参数关联起来。
这里请注意区分cgroup 与 cgroups
subsystem 是一组资源控制块,一般包含以下几项。
- blkio 设置块设备IO访问控制
- cpu 设置cpu调度策略
- devices 控制设备在cgroup中的访问
- memory 用于控制内存占用
Linux 系统可以通过命令lssubsys -a查看更多支持的 subsystem
hierarchy 的功能是把一组cgroup串联成一个树状结构,这样的树便是一个 hierarchy ,通过树状结构Cgroups可以做到继承。比如,系统通过cgroup1限制CPU,有个服务还需要同时限速内存,那么可以创建cgroup2继承于cgroup1并限制内存。同时cgroup2的限制只在cgroup2内部,cgroup1中的服务并不受cgroup2限制内存的影响。
三大组件相互关系
系统创建新的 hierarchy 后,系统中所有进程都会加入这个 hierarchy 的cgroup根节点,这个根节点是 hierarchy 默认创建。
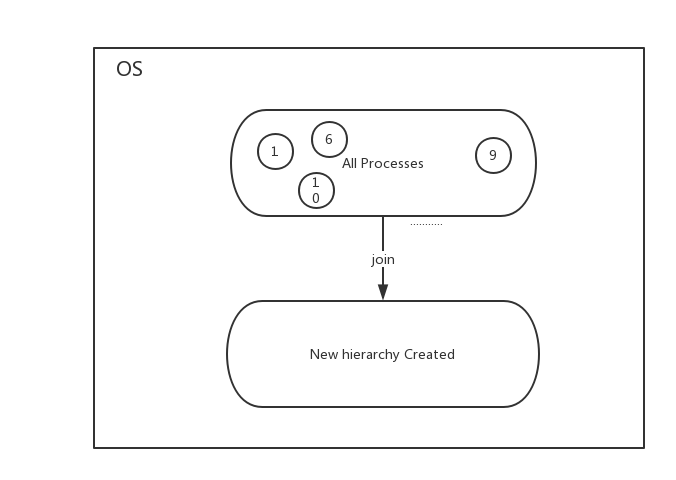
一个 subsystem 只能附加在 一个 hierarchy 上面。
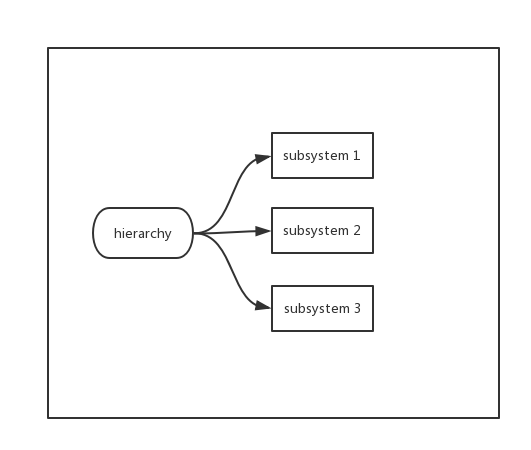
一个 hierarchy 附加多个 subsystem。
一个进程可以作为多个 cgroup 的成员,但这些cgroup必须在不同的 hierarchy 中。
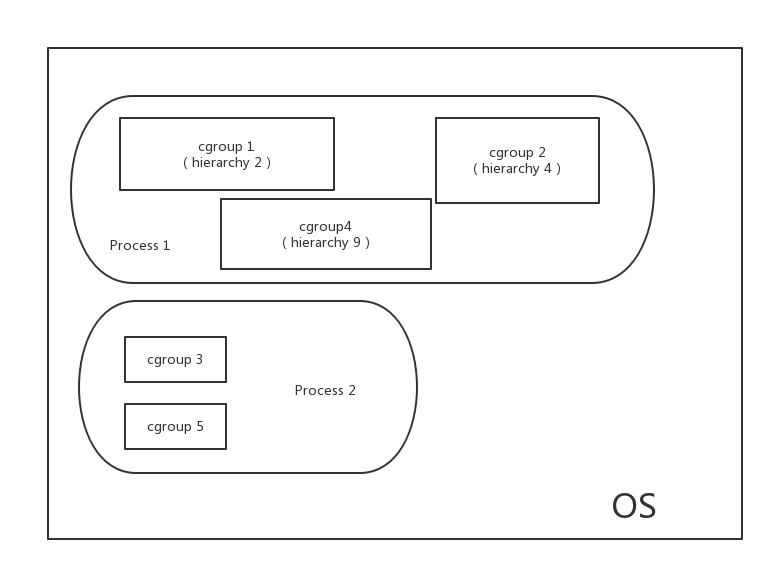
一个进程 fork出子进程时,子进程与父进程是在一个cgroup中的,也可以根据需要移动到其他cgroup里。
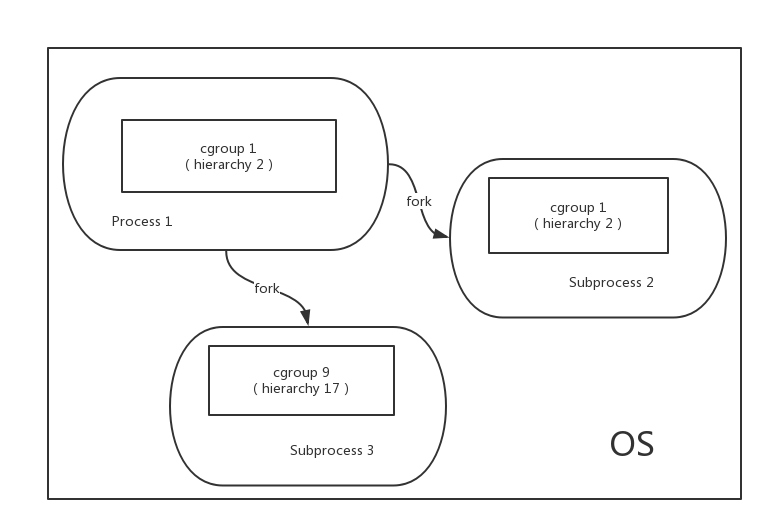
Kernel 接口
Cgroups 中的 hierarchy 是一种树状的组织结构,Kernel为了使Cgroup配置更加直观,是通过一个虚拟树状文件系统配置Cgroups的,通过层级的目录虚拟出cgroup树。
下面演示如何操作cgroups。
1.首先创建并挂载一个hierarchy (cgroup树)
1
2
3
4
| $ mkdir cgroup-test
$ sudo mount -t cgroup -o none,name=cgroup-test cgroup-test ./cgroup-test
$ ls ./cgroup-test
cgroup.clone_children cgroup.event_control cgroup.procs cgroup.sane_behavior notify_on_release release_agent tasks
|
- cgroup.clone_children cpuset的subsystem会读取这个配置文件,改文件值为1(默认0),子cgroup会继承父cgroup的cpuset的配置。
- cgroup.procs 是树中当前cgroup中的进程组ID。
- notify_on_release 与 release_agent 一起使用,前者用于标识当这个cgroup最后一个进程退出后是否执行了后者,后者是一个路径,通常用作进程退出后自动清理不在使用的cgroup。
- tasks 标注 该cgroup下面的进程ID,如果把一个进程ID写到tasks文件中,便会把相应的进程加入到这个cgroup中。
2.接着刚刚创建好的hierarchy上的cgroup根节点中扩展出两个子cgroup。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| $ cd cgroup-test
$ sudo mkdir cgroup-1
$ sudo mkdir cgroup-2
tree
.
|-- cgroup-1
| |-- cgroup.clone_children
| |-- cgroup.event_control
| |-- cgroup.procs
| |-- notify_on_release
| `-- tasks
|-- cgroup-2
| |-- cgroup.clone_children
| |-- cgroup.event_control
| |-- cgroup.procs
| |-- notify_on_release
| `-- tasks
|-- cgroup.clone_children
|-- cgroup.event_control
|-- cgroup.procs
|-- cgroup.sane_behavior
|-- notify_on_release
|-- release_agent
`-- tasks
2 directories, 17 files
|
可以看出在一个cgroup的目录下创建文件夹时,kernel会把这个文件夹记为这个cgroup的子cgroup,他们会继承cgroup的属性。
3.在cgroup中添加移动进程
我们刚刚说过,一个进程在一个Cgroups的hierarchy 中,只能在一个cgroup节点存在,系统所有进程都会默认在根节点存在,可以将进程移动到其他cgroup节点,只需要将进程ID写到移动到的cgroup节点的tasks文件即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| $ cd cgroup-1
$ sudo sh -c "echo $$">> tasks
$ cat /proc/$$/cgroup
12:name=cgroup-test:/cgroup-1
11:hugetlb:/user/500.user/17.session
10:perf_event:/user/500.user/17.session
9:blkio:/user/500.user/17.session
8:freezer:/user/500.user/17.session
7:devices:/user/500.user/17.session
6:memory:/user/500.user/17.session
5:cpuacct:/user/500.user/17.session
4:cpu:/user/500.user/17.session
3:cpuset:/
2:name=systemd:/user/500.user/17.session
|
发现进程已经被加入到cgroup-test:/cgroup-1中了。
Docker中,引擎通过为每个container 创建 cgroup,并通过cgroup 去配置资源限制和资源监控。
